고차원 순환 신경망을 이용한 음성 모델링
본 논문은 장기 의존성 학습에서 발생하는 기울기 소실 문제를 해결하기 위해 다중 이전 시점으로부터의 연결을 추가한 고차원 순환 신경망(HORNN)을 제안한다. ReLU와 sigmoid 활성화 함수에 대해 각각 설계된 HORNN 구조는 기존 RNN 대비 4.2%~6.3% 낮은 WER을 달성했으며, 파라미터와 연산량을 20%~50% 수준으로 줄인 투사형 HORNN(HORNNP)도 LSTM과 동등한 성능을 보였다.
저자: Chao Zhang, Philip Woodl
본 논문은 장기 의존성을 학습하는 순환 신경망(RNN)에서 발생하는 기울기 소실 문제를 해결하고, 동시에 LSTM이 갖는 파라미터·연산량 과다 문제를 완화하기 위해 고차원 순환 신경망(HORNN)이라는 새로운 구조를 제안한다. 기존 RNN은 현재 은닉 상태 hₜ 가 바로 이전 상태 hₜ₋₁ 과 현재 입력 xₜ 만을 이용해 계산되는 1차 마코프 의존성을 갖는다(식 1). 이 구조는 시간적으로 멀리 떨어진 정보가 순차적으로 전달되면서 기울기가 급격히 감소하는 기울기 소실(vanishing gradient) 현상을 초래한다. LSTM은 메모리 셀 cₜ 와 입력·망각·출력 게이트(i, f, o)를 도입해 장기 정보를 직접 보존하지만, 게이트당 파라미터가 추가돼 전체 파라미터 수가 4배로 늘어나는 단점이 있다.
HORNN은 이러한 한계를 고차 차수 연결(high‑order connections)이라는 간단한 아이디어로 극복한다. 구체적으로, 현재 은닉 상태 hₜ 를 계산할 때 hₜ₋ₙ (n > 1)과 같은 다중 이전 은닉 상태를 직접 입력에 연결한다. ReLU 기반 HORNN은 다음과 같이 정의된다.
hₜ = f(W xₜ + U₁ hₜ₋₁ + Uₙ hₜ₋ₙ + b) (식 4)
여기서 Uₙ 은 고차 연결의 가중치 행렬이며, n 은 실험적으로 최적값을 찾는다. sigmoid 기반 HORNN은 고차 연결을 직접 sigmoid 입력에 더해 다음과 같이 설계한다.
hₜ = f(W xₜ + U₁ hₜ₋₁ + Uₙ hₜ₋ₙ + hₜ₋ₘ + b) (식 5)
이때 m 은 추가적인 고차 연결을 의미한다. 이러한 구조는 역전파 시 ∂F/∂hₜ₋₁ 이 여러 경로를 통해 합산되도록 하여 기울기 소실을 수학적으로 완화한다(식 3).
하지만 고차 연결을 도입하면 파라미터 수가 증가한다. 이를 해결하기 위해 저자들은 LSTMP와 동일한 투사 레이어 P (차원 Dₚ) 를 도입, U₁ 과 Uₙ 을 Uₚ₁ P, Uₚₙ P 로 저차원 근사한다. 이때 전체 파라미터 수는
Dₕ Dₚ + (Dₓ + 2 Dₚ) Dₕ + Dₕ
가 되며, Dₕ ≫ Dₚ 인 경우 약 2 Dₕ / 3 Dₚ 비율로 감소한다. 계산 복잡도 측면에서도 HORNNP는 LSTMP 대비 3/5 이하의 곱셈‑덧셈 연산만을 요구한다.
실험은 영국 BBC 방송의 다중 장르 데이터(MGB3)에서 수행되었다. 전체 275 시간(275h) 데이터와 그 하위 55 시간(55h) 서브셋을 사용했으며, 63 k 단어 어휘와 3‑그램 언어 모델을 적용했다. 입력 특징은 40 dB 로그‑멜 필터뱅크에 Δ계수를 추가한 80 d 차원이며, 각 시점에 5프레임 지연을 적용했다. 모델은 단일 은닉층(크기 Dₕ = 500)과 투사 차원 Dₚ = 250을 기본으로 하였고, 학습은 교차 엔트로피 손실과 뉴보브+학습률 스케줄러를 사용했다.
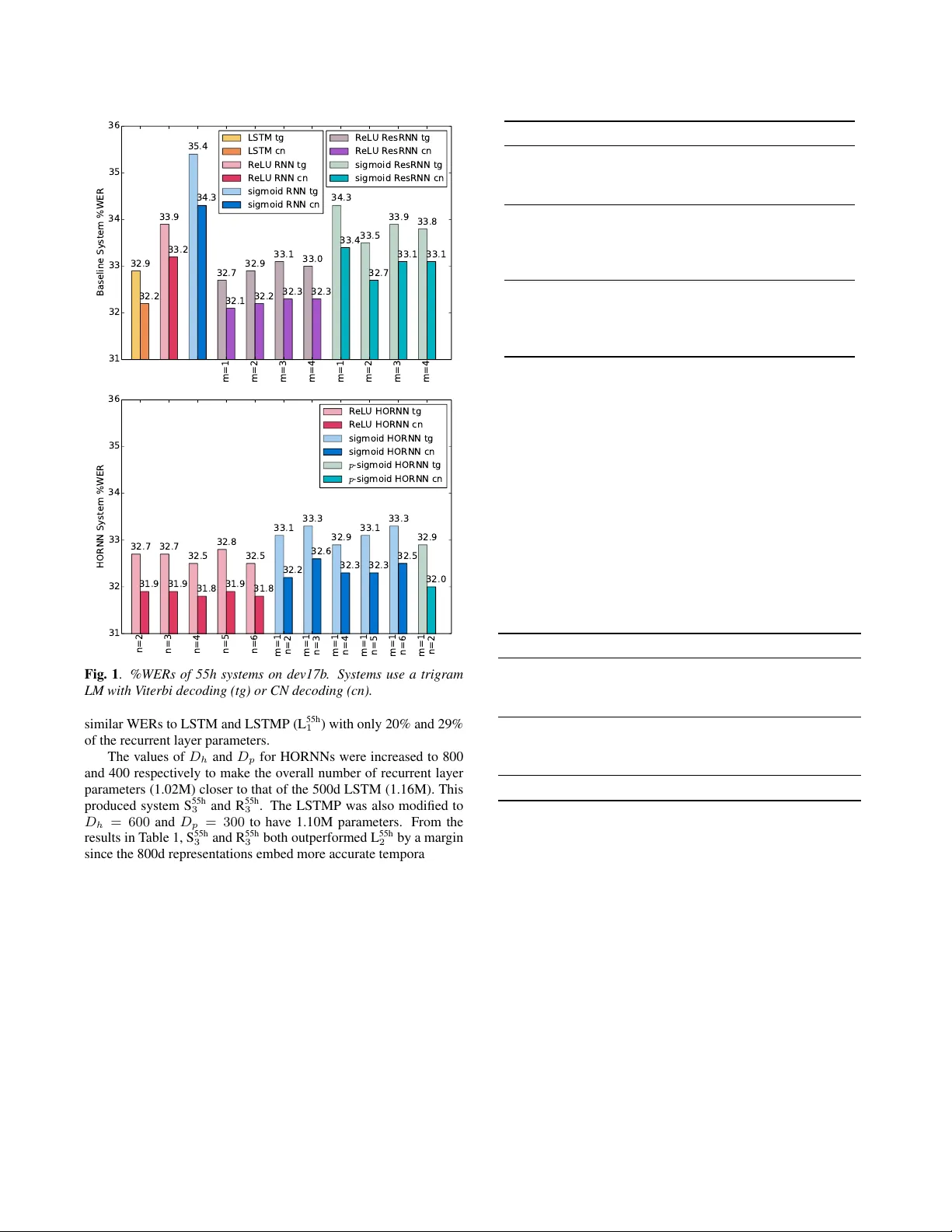
첫 번째 실험에서는 55h 데이터에 대해 다양한 n (2~6)과 m (1~4) 값을 탐색했다. 결과는 다음과 같다. ReLU 기반 HORNN은 LSTM과 동등하거나 약간 낮은 WER을 기록했으며, ResRNN(잔차 연결)보다도 우수했다. sigmoid 기반 HORNN은 ResRNN 대비 뚜렷히 개선되었고, LSTM 수준의 성능을 달성했다. 최적 구조는 ReLU HORNN에서 n = 4, sigmoid HORNN에서 m = 1, n = 2 로 설정되었다.
두 번째 실험에서는 투사형 모델(HORNNP)과 투사형 LSTM(LSTMP)을 비교했다. 단일 층(1L) 설정에서 LSTMP는 0.79 M 파라미터, HORNNP는 0.42 M 파라미터를 사용했으며, 두 모델 모두 비슷한 WER(≈ 31.9 %)을 보였다. 투사 차원을 250으로 더 줄인 경우 HORNNP는 파라미터 0.23 M으로 감소했음에도 여전히 LSTM 대비 큰 성능 저하가 없었다. 다층(2L, 3L) 확장 실험에서도 HORNNP는 LSTMP와 비슷한 WER을 유지하면서 파라미터와 연산량을 절반 이하로 낮췄다.
전체적으로 HORNN과 HORNNP는 (1) 장기 의존성 학습에서 기울기 소실을 효과적으로 완화하고, (2) 파라미터와 연산량을 크게 절감하며, (3) 실제 음성 인식 시스템에서 LSTM을 대체할 수 있는 실용적인 대안임을 입증한다. 특히, 고차 연결을 입력에 직접 결합하는 간단한 설계가 복잡한 게이트 구조 없이도 장기 정보를 전달할 수 있음을 보여준다. 향후 연구에서는 고차 연결의 깊이와 간격을 동적으로 학습하거나, Transformer와 결합하는 방안이 고려될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기