스파스 신호 복원을 위한 임계값 기반 알고리즘 비교
본 논문은 압축 센싱 환경에서 스파스 신호를 복원하기 위해 널리 사용되는 세 가지 임계값 기반 알고리즘인 Orthogonal Matching Pursuit(OMP), Iterative Hard Thresholding(IHT), Single Iteration Reconstruction Algorithm(SIRA)을 실험적으로 비교한다. 복원 정확도와 실행 시간을 기준으로 다양한 샘플 수에서 성능을 평가한 결과, SIRA가 가장 빠른 실행 시간과 …
저자: Tamara Koljensic, Caslav Labudovic
본 논문은 압축 센싱(Compressive Sensing, CS) 이론에 기반한 스파스 신호 복원 문제를 다루며, 특히 임계값 기반 알고리즘 세 가지—Orthogonal Matching Pursuit(OMP), Iterative Hard Thresholding(IHT), Single Iteration Reconstruction Algorithm(SIRA)—의 성능을 실험적으로 비교한다. 서론에서는 전통적인 나이퀴스트 샘플링이 요구하는 높은 샘플링 레이트와 그에 따른 저장·전송 비용을 지적하고, CS가 이러한 문제를 해결하기 위해 신호가 특정 변환 도메인(예: 푸리에)에서 스파스함을 가정하고 무작위 측정을 통해 적은 샘플만으로도 정확한 복원이 가능함을 설명한다. 또한, 선형 프로그래밍 기반의 Basis Pursuit, Dantzig Selector와 같은 방법은 정확하지만 계산량이 많아 실시간 응용에 부적합하므로, 그리디 기반 OMP와 임계값 기반 IHT, SIRA와 같은 경량 알고리즘이 연구되고 있음을 언급한다.
이론 섹션에서는 CS의 기본 수식 f = Ψp (f는 원본 신호, Ψ는 변환 행렬, p는 스파스 계수 벡터)와 측정 모델 d = Φf = ΦΨp를 제시한다. 여기서 Φ는 무작위 측정 행렬이며, Ψ와 Φ 사이의 무관성(incoherence)이 복원 성공에 필수적임을 강조한다.
알고리즘 설명에서는 OMP의 그리디 선택 과정(잔차와 가장 높은 상관을 보이는 열 선택 → 최소 제곱 해 → 잔차 업데이트)을 단계별로 제시하고, 종료 조건은 잔차가 사전 정의된 임계값 이하가 될 때이다. IHT는 목표 함수를 ‖d - ΦΨp‖₂² + λ‖p‖₀ 형태로 설정하고, 매 반복마다 선형 업데이트 후 하드 임계값 연산(Hₖ)으로 상위 K개의 계수만 남긴다. K는 사전에 알려진 스파시티 수준이며, 수렴 조건은 ‖p^{(t+1)} - p^{(t)}‖₂ < ε 혹은 최대 반복 횟수이다. SIRA는 측정된 시계열을 직접 DFT하여 초기 스펙트럼을 얻고, 노이즈 분산을 추정해 임계값 T = (1/2)·10^{log10(1/N·∑|v|²)}·√(−log(P)) (여기서 P는 허용 오류 확률)로 설정한다. 임계값 초과 주파수 성분을 신호 성분으로 간주하고, 해당 위치에 대해 최소제곱법으로 정확한 진폭을 재계산한다. SIRA는 사전 K값이 필요 없으며, 한 번의 변환과 임계값 판별만으로 복원을 마친다.
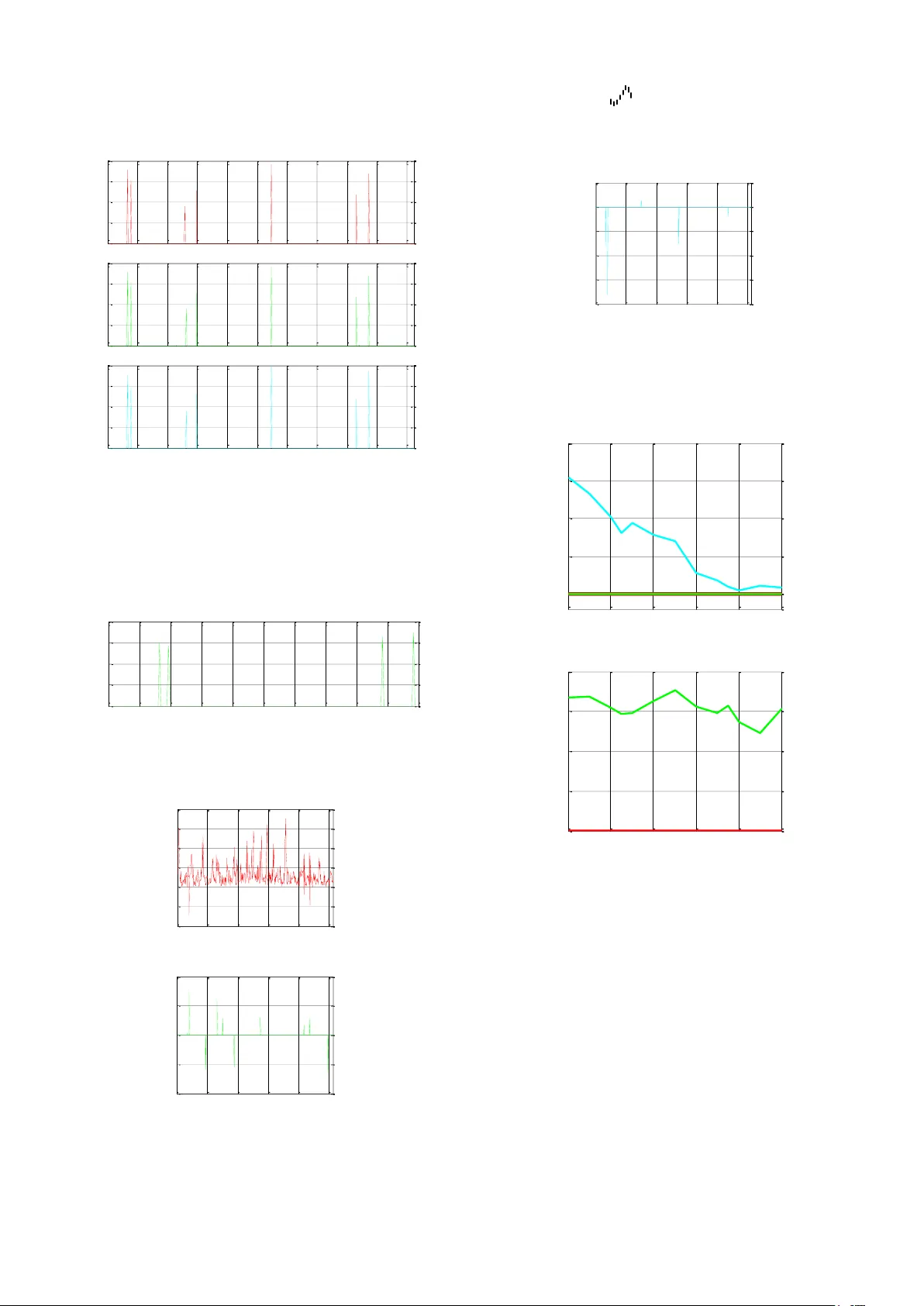
실험에서는 7개의 서로 다른 진폭을 가진 사인파 성분으로 구성된 밴드 제한 스파스 신호를 사용하였다. 신호 길이 N=512이며, 각 성분은 서로 다른 주파수와 진폭(3.5, 3, 1.75, 2.5, 3.75, 2.3, 3.3)으로 설정되었다. 측정 샘플 수 M을 200, 225, 250, 275, 300으로 변화시켜 각 알고리즘의 복원 오류와 실행 시간을 측정하였다. 오류는 원본 DFT와 복원 DFT의 최대 진폭 차이로 정의했으며, 실행 시간은 MATLAB 환경에서 초 단위로 기록하였다.
표 1과 그림 2~5를 통해 결과를 요약하면 다음과 같다.
- SIRA는 모든 M 값에서 가장 낮은 오류(최소 9.7×10⁻⁶)와 가장 짧은 실행 시간(≈0.01 s)를 기록하였다. 특히 M=200일 때도 오류가 10⁻⁵ 수준으로 충분히 정확했다.
- OMP는 샘플 위치 탐지 능력이 뛰어나 M이 증가할수록 더 많은 위치를 정확히 찾았지만, 오류는 10⁻⁴ 수준으로 SIRA보다 크게 나타났다. 실행 시간은 SIRA보다 약간 길었지만 여전히 0.04 s 이하였다.
- IHT는 K값을 정확히 알고 있을 경우(논문에서는 K=7) 오류가 10⁻⁵ 수준으로 우수했으며, 복원 품질은 SIRA와 비슷했지만 실행 시간은 0.06~0.10 s로 OMP보다 다소 길었다. K값이 잘못 설정되면 복원 품질이 급격히 저하되는 단점이 있다.
또한, 최소 샘플 수(M) 관점에서 SIRA는 170개의 샘플만으로도 성공적인 복원을 보였으며, IHT는 34개, OMP는 200개가 필요했다. 이는 SIRA가 샘플 효율성이 가장 높음을 의미한다.
결론에서는 세 알고리즘의 장단점을 정리한다. SIRA는 사전 신호 정보가 거의 없고 실시간 처리가 요구되는 상황에 최적이며, 구현이 간단하고 계산량이 매우 적다. IHT는 신호의 스파시티가 명확히 알려진 경우에 높은 정확도를 제공하지만, K값 설정이 필수적이다. OMP는 구현이 직관적이고 잔차 기반 선택으로 샘플 위치를 정확히 찾을 수 있지만, 오류가 상대적으로 크고 사전 임계값 설정이 필요하다. 논문은 향후 연구 방향으로 잡음이 있는 실제 환경에서의 성능 평가와, 하이브리드 알고리즘(예: OMP와 IHT 결합) 개발을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기