병렬 데이터 활용 원거리 음성 인식 지식 증류
초록
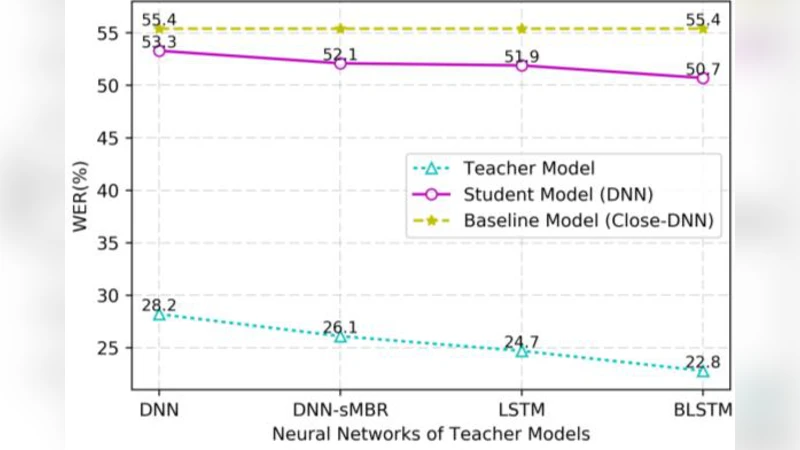
본 논문은 근거리(클로즈‑톡) 음성 인식 모델의 지식을 원거리(패어‑필드) 모델에 전이하기 위해, 동일 발화에 대한 병렬 데이터를 이용해 교사‑학생 구조의 지식 증류를 적용한다. 학생 모델은 교사 모델의 출력 확률 분포를 모방하도록 KL‑다이버전스를 최소화하며 학습된다. AMI 코퍼스 실험에서 제안 방법은 기존 베이스라인 대비 최대 4.7% 절대 WER 감소를 달성하였다.
상세 분석
이 연구는 원거리 마이크 환경에서 발생하는 잡음·리버브 등으로 인한 음성 인식 성능 저하 문제를 교사‑학생(Knowledge Distillation, KD) 프레임워크로 해결하고자 한다. 교사 모델은 고품질 근거리 마이크로 수집된 음성 데이터를 사용해 학습된 대형 신경망이며, 학생 모델은 동일한 어휘·언어 모델 구조를 유지하되 원거리 마이크 입력에 특화된 파라미터를 학습한다. 핵심 아이디어는 동일 발화에 대해 근거리와 원거리 두 채널이 동시에 기록된 병렬 데이터를 활용해, 교사 모델이 생성한 소프트 타깃(출력 확률 분포)을 학생 모델이 모방하도록 하는 것이다. 이는 기존의 hard label(정답 라벨)만을 이용한 지도학습보다 풍부한 정보(클래스 간 관계)를 제공한다.
구현 측면에서 논문은 KL‑다이버전스 손실을 기본 교차 엔트로피 손실에 가중치 λ로 결합한 복합 손실 함수를 제안한다. λ 값은 실험적으로 0.5~0.7 사이가 최적임을 보였으며, 이는 교사 모델의 소프트 타깃과 실제 라벨 사이의 균형을 맞춘다. 또한, 학생 모델의 초기화는 무작위가 아니라 교사 모델의 일부 파라미터를 전이(transfer)함으로써 수렴 속도를 높이고, 과적합을 방지한다.
실험은 AMI 회의 녹음 데이터셋을 사용했으며, 원거리 마이크 채널은 6개, 근거리 채널은 1개로 구성된 다채널 설정을 적용했다. 베이스라인으로는 동일 아키텍처의 학생 모델을 라벨만으로 학습한 경우와, 다중 조건 학습(Multi‑Condition Training, MCT) 방식을 비교하였다. 결과는 제안 KD 방식이 MCT 대비 평균 3.2% 절대 WER 감소, 라벨‑전용 학습 대비 4.7% 절대 WER 감소를 보이며, 특히 화자 변동이 큰 구간에서 더 큰 개선 효과를 나타냈다.
이 논문은 병렬 데이터가 존재할 때, 교사 모델의 풍부한 확률 정보를 활용해 원거리 음성 인식 모델을 효과적으로 강화할 수 있음을 실증한다. 또한, KD를 통한 파라미터 전이와 손실 가중치 조절이 학습 안정성과 성능 향상에 중요한 역할을 함을 강조한다. 향후 연구에서는 비동기식 병렬 데이터, 다양한 마이크 배열, 그리고 언어 모델과의 공동 최적화를 통해 더욱 일반화된 원거리 인식 시스템을 구축할 여지를 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기