시암쌍신경망 기반 오디오 콘텐츠 검색
본 논문은 시암쌍(Siamese) 신경망을 이용해 오디오 클립을 128차원 벡터로 인코딩하고, 유클리드 거리·코사인 유사도로 유사한 소리를 검색하는 방법을 제안한다. 76개의 일상 소리 클래스를 포함한 YouTube 데이터셋(클래스당 100개)으로 학습·평가했으며, 균형·불균형 페어링 전략을 비교한다. 결과는 MAP 0.02~0.03, 첫 번째 정답 정확도(MP1) 0.31~0.44, 상위 25개(K) 정답 비율(MPK) 0.10~0.18 수준…
저자: Pranay Manocha, Rohan Badlani, Anurag Kumar
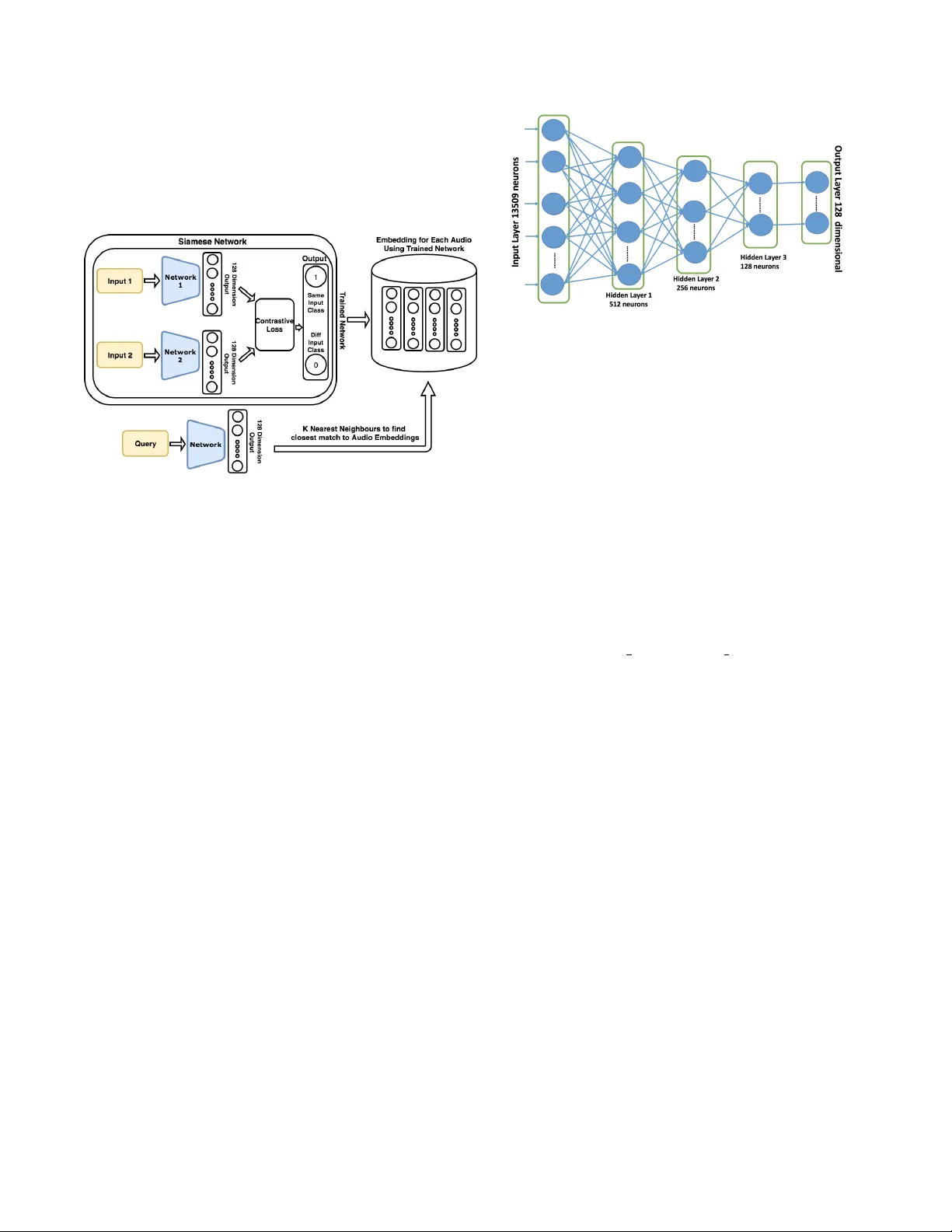
본 논문은 “Content‑Based Audio Retrieval” 즉, 사용자가 제공한 오디오 클립과 의미적으로 유사한 다른 클립들을 데이터베이스에서 찾아내는 문제에 초점을 맞춘다. 기존의 오디오 핑거프린팅 기법은 정확히 같은 녹음이나 매우 유사한 파형을 찾는 데는 효율적이지만, 의미적 유사성을 포착하기에는 한계가 있다. 이를 극복하고자 저자들은 시암쌍 신경망(Siamese Neural Network, 이하 SNN)을 활용해 오디오를 고차원 임베딩 공간에 매핑한다.
SNN은 두 개의 동일한 서브네트워크(“쌍”)로 구성되며, 각각에 서로 다른 오디오 샘플을 입력한다. 네트워크는 입력을 128‑차원 벡터로 압축하고, 두 벡터 사이의 유클리드 거리를 계산한다. 학습 목표는 같은 클래스(예: “개 짖는 소리”)에 속하는 샘플은 거리를 최소화하고, 다른 클래스에 속하는 샘플은 사전에 정의된 마진(m)보다 큰 거리를 유지하도록 하는 대조 손실(Contrastive Loss)이다.
입력 특징은 2초 길이의 로그 스펙트로그램이다. 1024‑point FFT와 64 ms 윈도우, 32 ms 오버랩을 사용해 79 × 171 = 13 509 차원의 벡터를 만든 뒤, 이를 MLP(512‑256‑128) 구조에 투입한다. 각 은닉층은 ReLU 활성화와 0.3 드롭아웃을 적용해 과적합을 방지한다. 최종 128‑차원 출력이 오디오의 “시맨틱 지문” 역할을 한다.
데이터는 ESC‑50, US8K, TUT‑2016 등 세 개의 공개 데이터베이스에서 추출한 76개의 일상 소리 클래스를 기반으로, 각 클래스당 100개의 YouTube 녹음(총 약 5 000개)을 수집한다. 녹음은 길이와 품질을 기준으로 필터링했으며, 2초 길이로 슬라이스한다. 학습‑검증‑테스트 비율은 70‑10‑20이며, 페어링 방식은 두 가지를 실험한다. 첫 번째는 양성·음성 페어를 동일하게 구성한 균형(Balanced) 방식(NBR), 두 번째는 모든 가능한 음성 페어를 포함한 불균형(Unbalanced) 방식(NUR)이다.
검색 단계에서는 데이터베이스의 모든 오디오를 사전에 학습된 서브네트워크에 통과시켜 128‑차원 임베딩을 저장한다. 쿼리 오디오도 동일 네트워크를 거쳐 임베딩을 얻고, 유클리드 거리 혹은 코사인 유사도로 전체 데이터베이스와의 거리를 계산한다. 거리 순으로 정렬한 뒤 상위 K개의 결과를 반환한다.
평가 지표는 평균 정밀도(MAP), 첫 번째 정답 정확도(MP1), 그리고 K개 상위 결과의 정밀도(MPK)이며, K는 1부터 30까지 변화를 살펴본다. 실험 결과는 다음과 같다. 유클리드 거리 기반이 코사인보다 MAP에서 약 0.01 정도 높은 성능을 보였으며, 이는 학습 시 거리 측정에 유클리드 거리를 사용했기 때문이다. NUR 모델이 NBR보다 전반적으로 높은 MP1(0.33→0.44)과 MPK(0.10→0.18) 값을 기록했으며, 이는 음성 페어를 많이 제공함으로써 보다 구분력 있는 임베딩을 학습했기 때문이다. 그러나 MAP가 0.02~0.03 수준에 머무른 점은 현재 임베딩이 의미적 유사성을 충분히 포착하지 못함을 의미한다.
논문의 주요 기여는 (1) 시암쌍 구조를 오디오 도메인에 적용해 의미 기반 검색 가능성을 제시한 점, (2) 균형·불균형 페어링이 임베딩 품질에 미치는 영향을 실험적으로 분석한 점이다. 한편, 제한점으로는 (가) 단순 MLP 구조가 시간‑주파수 패턴을 충분히 학습하지 못함, (나) 고정 2초 클립에만 의존해 실제 환경의 다양한 길이와 잡음에 대한 일반화가 부족함, (다) 비교 대상이 되는 최신 오디오 임베딩 방법(예: CNN 기반, 사전학습 모델)과의 벤치마크가 없다는 점을 들 수 있다.
향후 연구 방향은 다음과 같다. 첫째, CNN‑RNN 혹은 Transformer 기반의 더 깊은 네트워크를 도입해 스펙트로그램의 지역적·시계열적 특성을 효과적으로 추출한다. 둘째, 트리플렛 손실(Triplet Loss)이나 N‑pair 손실을 활용해 더 강력한 거리 학습을 수행한다. 셋째, 데이터 증강(시간 스트레칭, 피치 변환, 잡음 추가)과 멀티스케일 입력을 통해 모델의 강건성을 높인다. 넷째, VGGish, YAMNet 등 대규모 사전학습된 오디오 모델과 결합해 전이 학습을 시도한다. 마지막으로, 다양한 길이와 복합 이벤트가 섞인 실제 멀티라벨 데이터셋을 활용해 실용적인 콘텐츠 기반 오디오 검색 시스템을 구축한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기