빅데이터와 클라우드 환경에서 터키어 과학 논문 자동 분류 시스템 구현
초록
**
본 연구는 Hadoop 기반 클라우드 인프라와 Apache Mahout의 Naive Bayes 알고리즘을 활용해 터키어 과학 논문을 자동으로 분류한다. PDF에서 텍스트를 추출하고 Zemberek로 전처리한 뒤 HDFS에 저장, Mahout 파이프라인(seqdirectory → seq2sparse → split → trainnb → testnb)으로 학습·테스트를 수행하였다. Google Cloud와 3대 노드 Hadoop 클러스터에서 89 %~91 %의 정확도를 달성했으며, 노드 수에 따른 처리 시간 변화를 분석하였다.
**
상세 분석
**
이 논문은 빅데이터 처리 프레임워크와 자연어 처리(NLP) 도구를 결합해 대규모 학술 문서의 자동 분류 문제를 해결하고자 한다. 먼저 데이터 수집 단계에서 터키어 학술지인 TÜBİTAK DergiPark에서 48 000여 건의 PDF를 크롤링하고, Apache Tika와 Zemberek를 이용해 텍스트를 추출·정제한다. 여기서 불용어(stop‑word)와 형태소 분석을 수행함으로써 언어 특유의 어미·접미사를 제거하고 어근 기반의 토큰을 확보한다.
전처리된 텍스트는 MongoDB에 임시 저장된 뒤, Hadoop Distributed File System(HDFS)으로 이동한다. HDFS는 데이터 복제와 장애 복구를 제공해 대용량 파일을 안전하게 보관한다. 이후 Mahout의 seqdirectory 명령으로 원시 텍스트를 시퀀스 파일로 변환하고, seq2sparse 단계에서 TF‑IDF 가중치를 적용한 벡터 공간 모델을 만든다. split 명령으로 전체 데이터를 60 % 학습, 40 % 테스트 셋으로 무작위 분할한다.
학습 단계에서는 Mahout의 trainnb(Naive Bayes) 알고리즘을 사용한다. Naive Bayes는 조건부 독립 가정을 기반으로 고차원 희소 벡터에서도 빠른 학습이 가능하므로, 수십만 차원의 텍스트 특성을 효율적으로 처리한다. 모델은 라벨 인덱스와 함께 HDFS에 저장된다. 테스트 단계는 testnb로 수행되며, 예측 라벨과 실제 라벨을 비교해 혼동 행렬, 정확도, Kappa, 가중 정밀도·재현율·F1 점수를 산출한다.
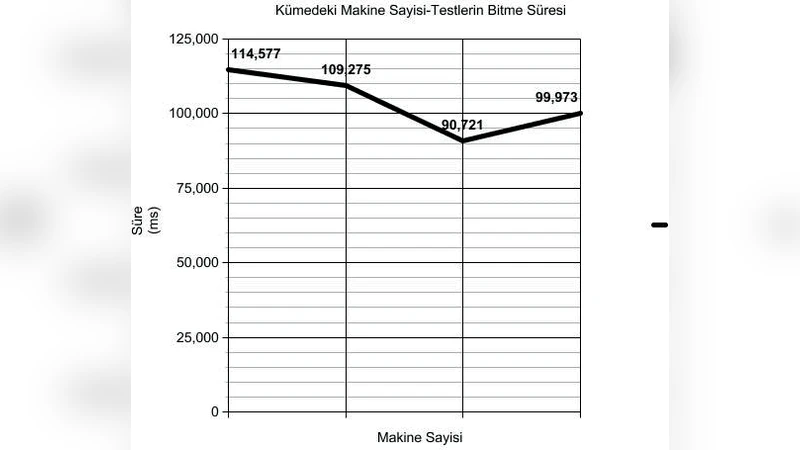
실험 결과, Google Cloud 상 3대 노드 Hadoop 클러스터에서 전체 19 066건의 문서에 대해 89.77 %의 정확도와 Kappa 0.8611을 기록했다. 노드 수를 4, 5, 6대로 확대했을 때 처리 시간은 각각 114 577 ms, 109 275 ms, 90 721 ms로 감소했으며, 정확도는 91.48 %까지 상승했다. 이는 데이터 분산과 병렬 연산이 성능에 미치는 긍정적 영향을 입증한다.
또한, Mahout와 Spark를 연계한 spark-trainnb·spark-testnb 파이프라인을 적용해 동일 데이터셋에 대해 91.48 % 정확도를 얻었으며, Spark의 메모리 기반 연산이 I/O 병목을 완화한다는 점을 강조한다.
논문은 빅데이터 기술이 전통적인 텍스트 분류 한계를 넘어설 수 있음을 실증적으로 보여준다. 특히, 터키어와 같이 형태소가 복잡한 언어에 대해 Zemberek와 같은 언어 특화 전처리기를 결합하면 Naive Bayes와 같은 단순 모델도 높은 성능을 달성할 수 있다. 다만, 라벨 불균형 문제와 고차원 특성의 희소성으로 인한 과적합 위험을 완화하기 위한 차원 축소(LDA, Word2Vec)나 딥러닝 기반 모델과의 비교 연구가 향후 과제로 남는다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기