원시 파형을 이용한 샘플 레벨 CNN 기반 음악 자동 태깅 향상
본 논문은 기존 샘플‑레벨 1‑D CNN 구조에 ResNet과 SENet의 핵심 블록을 도입하고, 다중 레벨 특징 집합을 활용함으로써 MagnaTagATune 데이터셋에서 최첨단 성능을 달성하고 Million Song Dataset에서도 경쟁력 있는 결과를 얻었다. 또한 SE 블록의 채널 재조정 메커니즘을 시각·정량적으로 분석하여 1‑D CNN이 입력 파형을 어떻게 단계별로 처리하는지 설명한다.
저자: Taejun Kim, Jongpil Lee, Juhan Nam
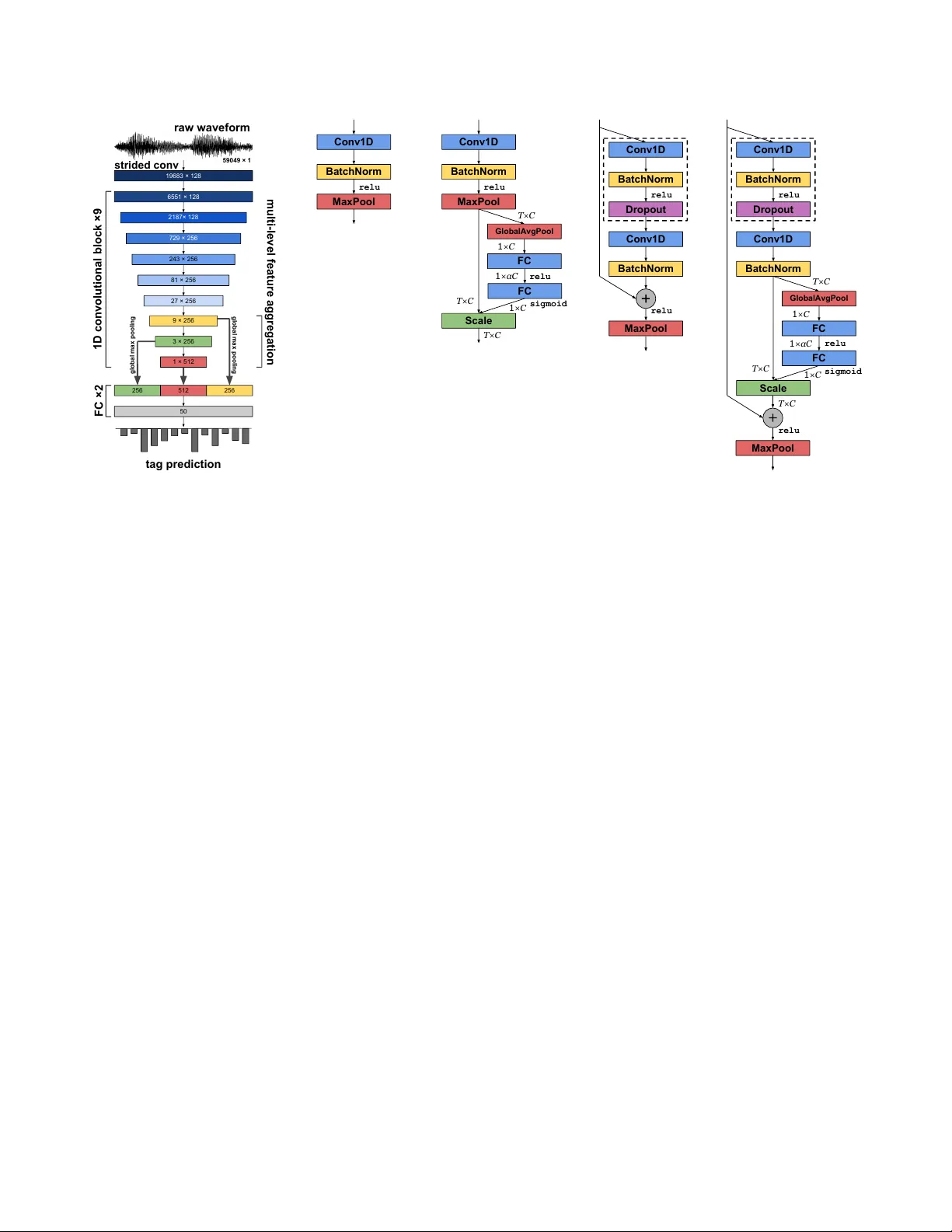
본 논문은 음악 자동 태깅을 위한 end‑to‑end 학습 접근법을 심층 탐구한다. 기존 연구에서는 주로 멜‑스펙트로그램과 같은 2‑D 시간‑주파수 표현을 입력으로 사용했으며, 이는 윈도우 크기·홉 사이즈 등 전처리 파라미터에 민감한 단점이 있었다. 이러한 한계를 극복하고자 raw waveform을 직접 입력으로 사용하는 1‑D CNN이 제안되었고, 특히 Lee et al. (2017)의 샘플‑레벨 CNN이 작은 3‑point 필터를 이용해 성공적인 결과를 보였다. 그러나 해당 모델은 기본적인 VGG‑style 블록만을 사용했으며, 최근 이미지 분야에서 제시된 Residual Network(ResNet)와 Squeeze‑and‑Excitation Network(SEnet)의 고급 블록을 적용하지 않았다.
이에 저자들은 세 가지 주요 기여를 제시한다. 첫째, 기존 샘플‑레벨 CNN에 ResNet의 스킵 연결과 SENet의 채널 재조정(SE) 블록을 도입한다. Res‑n 블록은 n=1 혹은 n=2개의 Conv 레이어와 스킵 경로를 포함하며, n=2일 경우 두 Conv 사이에 dropout(0.2)을 삽입해 과적합을 방지한다. 둘째, SE 블록은 전역 평균 풀링을 통해 채널별 통계량을 압축(squeeze)하고, 두 개의 전결합 레이어(확장 비율 α=16)를 거쳐 채널 간 상호작용을 모델링한 뒤(sigmoid) 스케일링을 통해 원본 피처를 재조정한다. 기존 SENet과 달리 차원을 축소하지 않고 확대함으로써 더 풍부한 채널 표현을 유지한다. 셋째, 다중 레벨 특징 집합(multi‑level feature aggregation)을 도입해 마지막 세 블록의 출력을 전역 최대 풀링 후 연결(concatenation)하고, 이를 전결합 레이어에 입력한다. 이는 서로 다른 추상화 수준의 피처를 동시에 활용해 태그 구분 능력을 강화한다.
실험은 두 대규모 데이터셋인 MagnaTagATune(MTAT)와 Million Song Dataset(MSD)를 사용한다. 두 데이터셋 모두 50개의 가장 빈번한 태그를 선택하고, 각 곡을 29초(59049 샘플) 길이로 자른 뒤 10개의 세그먼트로 나누어 학습·평가한다. 평가 지표는 태그별 ROC‑AUC의 평균이다. 학습은 SGD(Nesterov, momentum=0.9)와 초기 학습률 0.01을 사용하고, 검증 손실이 정체될 경우 학습률을 5배 감소시킨다. MTAT에서는 마지막 전결합 레이어 앞에 dropout(0.5)을 적용했으며, MSD에서는 별도 정규화를 적용하지 않았다.
성능 비교 결과, 기본 블록만 사용한 모델(0.9055 AUC, MTAT)보다 SE 블록을 적용한 모델이 0.9111, ReSE‑2 블록이 0.9113으로 현저히 높은 AUC를 기록했다. Res‑1은 오히려 성능이 감소했으며, Res‑2는 약간 개선되었지만 SE 대비 낮았다. 다중 레벨 집합을 사용했을 때 대부분의 모델에서 AUC가 0.002~0.004 정도 상승했으며, 특히 SE와 ReSE‑2에서 가장 큰 이득을 보였다. 훈련 시간 측면에서는 SE 블록이 기본 블록 대비 1.08배, ReSE‑2가 1.8배 소요돼 실시간 적용 가능성에 차이가 있다.
또한 저자들은 SE 블록의 내부 동작을 분석했다. 세 개의 대표 태그(클래식, 메탈, 댄스)를 선택해 각 블록의 시그모이드 활성값을 평균화하고 채널별로 정렬하였다. 첫 번째 블록은 볼륨 차이에 민감해 클래식(저음량)에서는 높은 활성값을, 메탈(고음량)에서는 낮은 값을 보였다. 중간 블록은 전반적인 특징을 추출하며 활성값 차이가 감소했고, 마지막 블록은 태그 구분에 중요한 채널을 다시 강조해 활성값이 크게 변동했다. 정량적 분석으로 각 레이어별 활성값 표준편차를 계산했을 때, 첫 레이어에서 가장 높고 중간 레이어에서는 낮으며, 마지막 레이어로 갈수록 다시 상승하는 패턴이 관찰되었다. 이는 초기 레이어가 전역적인 신호 정규화, 중간 레이어가 공통 저수준 피처 학습, 최종 레이어가 고차원 태그 구분 정보를 강화한다는 해석을 가능하게 한다.
결론적으로, 본 연구는 이미지 분야에서 검증된 Residual 및 Squeeze‑and‑Excitation 메커니즘을 raw waveform 기반 1‑D CNN에 성공적으로 전이시켰으며, 특히 채널 재조정(SE)과 잔차 학습(ResNet)을 결합한 ReSE 블록이 가장 높은 성능을 달성했다. 다중 레벨 특징 집합은 다양한 추상화 수준을 동시에 활용해 태깅 정확도를 향상시키는 효과적인 전략으로 확인되었다. MTAT에서는 최첨단 성능을 기록했으며, MSD에서도 경쟁력 있는 결과를 보여 일반화 가능성을 입증했다. 마지막으로 SE 블록의 내부 동작을 시각·정량적으로 분석함으로써 1‑D CNN이 입력 파형을 단계별로 어떻게 처리하는지에 대한 이해를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기