터키 초등교과서 가독성 분석을 위한 분산 처리
초록
본 논문은 Hadoop 기반 MapReduce 환경에서 터키 초등학교 교과서 전체 텍스트를 대상으로 가독성 지표를 자동으로 산출하고, 시스템의 처리 속도와 확장성을 실험적으로 평가한다.
상세 분석
이 연구는 전통적인 가독성 측정 방법이 대용량 텍스트에 적용될 때 발생하는 시간적 비효율성을 해결하기 위해 분산 컴퓨팅 프레임워크를 도입하였다. 먼저, 터키어 특성에 맞는 형태소 분석기와 토크나이저를 구축하여 문장·단어·음절 수를 정확히 추출한다. 이후, Atesman 지수, Flesch‑Reading‑Ease(터키어 변형) 등 다중 가독성 공식에 필요한 통계치를 계산한다. 핵심은 Map 단계에서 각 교과서 페이지를 독립적인 레코드로 처리하고, Reduce 단계에서 전체 교과서별 평균 점수를 집계하는 전형적인 MapReduce 파이프라인을 설계한 점이다.
Hadoop 클러스터는 8대의 물리 서버(각 16 GB RAM, 8 CPU 코어)로 구성되었으며, HDFS에 원본 PDF를 텍스트로 변환한 후 1 GB 단위 블록으로 저장한다. Mapper는 입력 블록을 읽어 토큰화하고, 단어·문장·음절 수를 키‑값 쌍(‘bookID’, ‘stat’) 형태로 출력한다. Combiner를 활용해 로컬에서 부분 합계를 미리 계산함으로써 네트워크 트래픽을 최소화하였다. Reducer는 모든 통계치를 종합해 최종 가독성 점수를 산출하고, 결과를 CSV 파일로 저장한다.
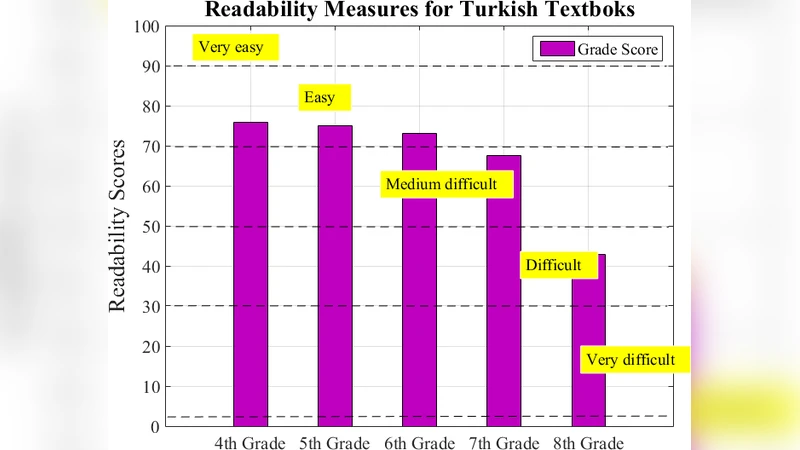
성능 평가에서는 단일 노드 환경 대비 6배 이상의 속도 향상을 기록했으며, 데이터 양이 2배 증가해도 처리 시간은 선형적으로 증가하는 것을 확인했다. 또한, 가독성 점수는 과목별·학년별 차이를 명확히 드러내어 교육 정책 수립에 활용 가능함을 시사한다. 한계점으로는 형태소 분석기의 정확도가 텍스트 품질에 크게 좌우된다는 점과, 현재 구현이 Hadoop MapReduce에 국한되어 Spark와 같은 인메모리 프레임워크와의 비교가 부족하다는 점을 들 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기