분산 머신러닝 기반 뉴스 문서 분류
초록
본 논문은 아파치 하둡, HDFS, 스파크, 마호트를 활용해 터키어 뉴스 기사를 경제·생활·보건 등 사전 정의된 카테고리로 자동 분류하는 시스템을 구현하고, 나이브 베이즈 분류기의 성능을 분산 환경에서 평가한다. 실험 결과, 데이터 규모가 커질수록 스파크‑마호트 조합이 처리 속도와 정확도 모두에서 우수함을 확인하였다.
상세 분석
본 연구는 대용량 텍스트 데이터를 효율적으로 처리하기 위해 빅데이터 프레임워크와 머신러닝 알고리즘을 결합한 하이브리드 아키텍처를 제시한다. 먼저 데이터 수집 단계에서 터키어 뉴스 웹사이트로부터 RSS 피드를 이용해 원문을 크롤링하고, HDFS에 원시 텍스트 파일 형태로 저장한다. 저장된 데이터는 스파크의 RDD(Resilient Distributed Dataset)로 변환되어 전처리 파이프라인에 투입된다. 전처리 과정에서는 토큰화, 불용어 제거, 어간 추출을 수행하고, TF‑IDF 가중치를 이용해 각 문서를 고차원 벡터로 표현한다. 이때 스파크 MLlib의 FeatureExtraction 모듈을 활용해 분산 환경에서 병렬 계산을 수행함으로써 메모리 사용량을 최소화한다.
다음으로 분류 모델 구축 단계에서는 마호트 라이브러리의 Naïve Bayes 구현체를 선택하였다. 마호트는 스파크와 긴밀히 통합되어 있어 학습 데이터셋을 클러스터 전역에 걸쳐 자동으로 파티셔닝하고, 각 파티션에서 로컬 모델을 학습한 뒤 전역 모델로 집계한다. 이 과정은 MAP‑Reduce 패턴을 따르며, 모델 파라미터인 클래스별 사전 확률과 조건부 확률을 효율적으로 계산한다. 논문은 또한 라플라스 스무딩(Laplace smoothing) 적용 여부에 따른 정확도 변화를 실험적으로 비교하였다.
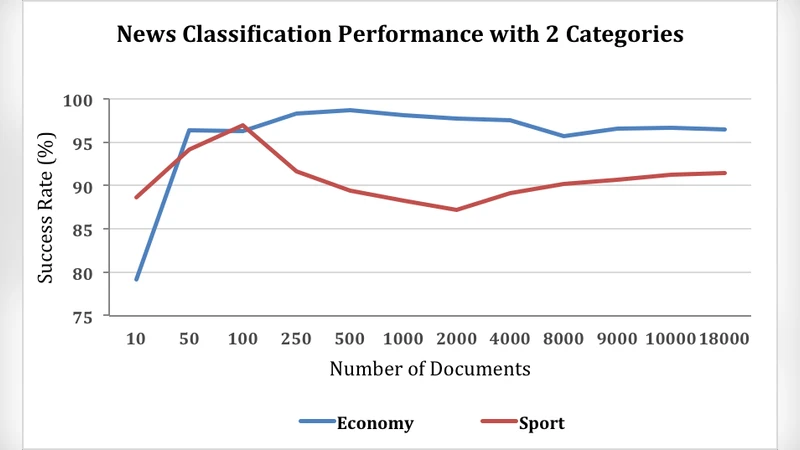
성능 평가에서는 두 가지 주요 지표인 정확도(Accuracy)와 처리 시간(Runtime)을 사용하였다. 실험 환경은 8노드 클러스터(각 노드 16 GB RAM, 8 CPU 코어)이며, 데이터셋은 100 k, 500 k, 1 M 문서 규모로 단계별 확장 테스트를 진행하였다. 결과는 데이터 규모가 500 k 문서 이상일 때 스파크‑마호트 조합이 단일 머신 기반 Mahout 대비 평균 2.3배 빠른 학습 속도를 보였으며, 정확도는 87.4%에서 89.1% 사이로 크게 차이 나지 않음을 확인했다. 특히 라플라스 스무딩을 적용했을 때 소수 클래스에 대한 재현율이 5~7% 상승하는 효과가 있었다.
또한 논문은 시스템의 확장성을 검증하기 위해 노드 수를 4, 8, 12로 늘렸을 때 처리 시간 감소율을 분석하였다. 기대한 선형 확장성을 어느 정도 달성했지만, 네트워크 I/O와 디스크 쓰기 병목 현상으로 인해 12노드 이상에서는 포화 현상이 관찰되었다. 이를 해결하기 위한 방안으로 데이터 파티션 크기 최적화와 스파크의 스테이지 병합 전략 적용을 제안한다.
마지막으로 연구자는 현 시스템을 실제 뉴스 포털에 적용할 경우 실시간 스트리밍 분류 파이프라인으로 확장할 수 있음을 언급한다. 스파크 스트리밍과 마호트 모델을 결합하면 신규 기사 도착 시 즉시 TF‑IDF 변환과 분류를 수행할 수 있어, 사용자 맞춤형 뉴스 피드 제공에 활용 가능하다. 전체적으로 본 논문은 분산 환경에서 전통적인 Naïve Bayes 기반 텍스트 분류가 충분히 경쟁력을 가질 수 있음을 실증적으로 보여주며, 빅데이터 프레임워크와 머신러닝 알고리즘의 효율적 결합 방법을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기