2그램 기반 음성 특징 생성으로 상표 유사성 평가
본 논문은 상표의 발음 유사성을 판단하기 위해 국제음성기호(IPA) 기반 2‑그램을 2차원 이미지 형태의 음성 특징(PF)으로 변환하고, 이를 합성곱 신경망(CNN)에 입력하여 92% 수준의 높은 정확도를 달성한 방법을 제시한다.
저자: Kyung Pyo Ko, Kwang Hee Lee, Mi So Jang
본 논문은 상표 등록 심사 과정에서 발생하는 “음성 유사성” 판단을 자동화하기 위한 새로운 접근법을 제시한다. 서론에서는 상표가 시각·음성·개념적 측면에서 혼동을 일으킬 수 있음을 언급하고, 특히 음성 유사성 판단이 현재는 전문가의 주관적 판단에 의존하고 있어 일관성이 부족함을 지적한다. 기존 연구로는 Soundex, Metaphone, ALINE 등 음성 유사도 알고리즘이 소개되지만, 이들 방법은 인덱싱 제한, 모음 제거, 혹은 복잡한 특징 설계 등으로 실제 상표명에 적용하기에 한계가 있다.
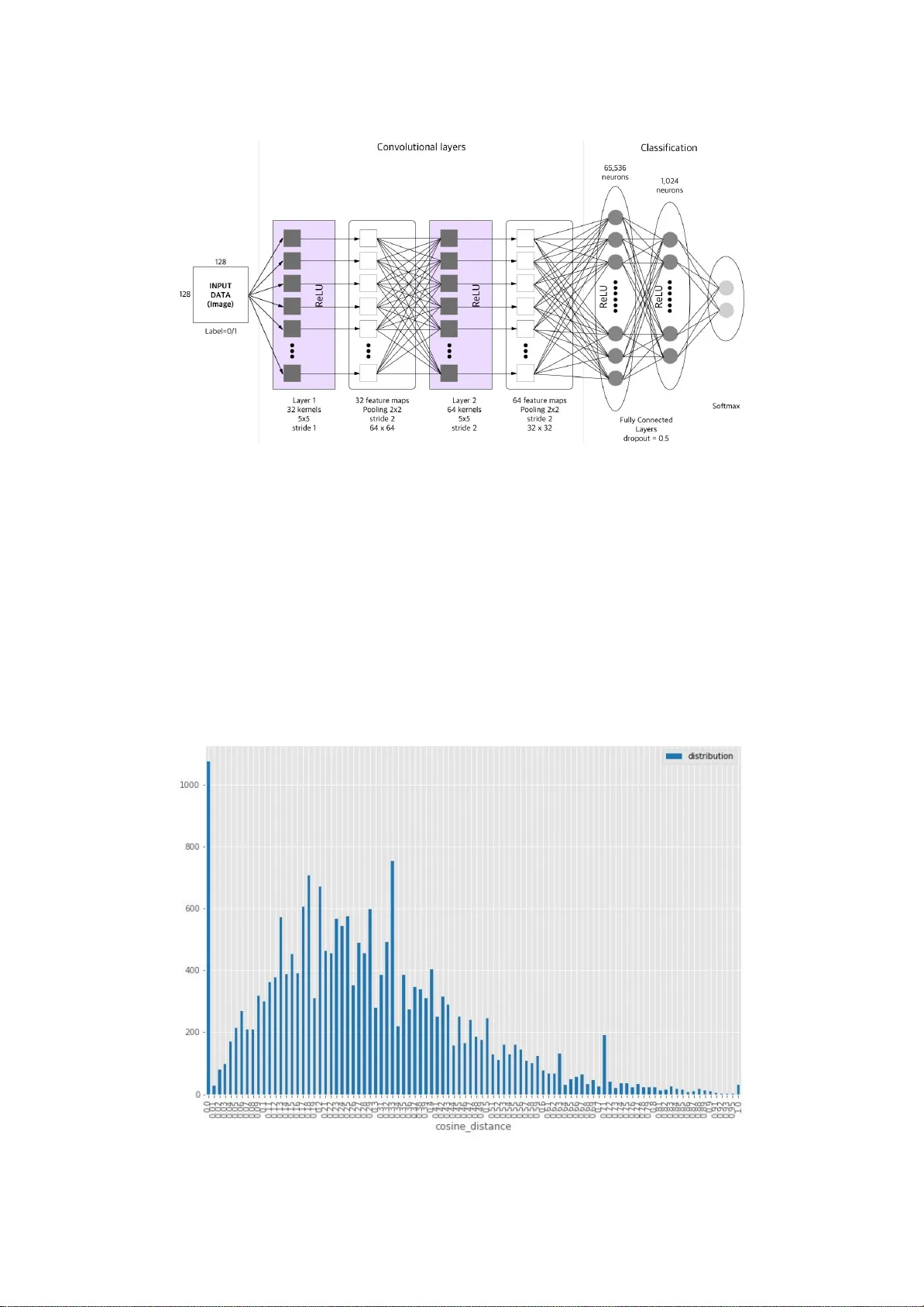
제안된 방법은 네 단계로 구성된다. 첫째, 상표명을 국제음성기호(IPA) 혹은 로마자 표기로 변환한다. 이를 위해 Kroman-py와 English_to_IPA 같은 오픈소스 변환기를 활용한다. 둘째, 변환된 문자열을 2‑그램(바이트 수준)으로 슬라이딩 윈도우 방식으로 분할한다. 예를 들어 “TEXT”는 ‘-T’, ‘TE’, ‘EX’, ‘XT’, ‘T_’ 로 나뉜다. 셋째, 45개의 IPA 기호(시작 ‘-’, 종료 ‘_’ 포함)를 0~127 정수값에 매핑하는 사전을 구축하고, 각 2‑그램에 대해 (u, v) 좌표를 할당한다. 여기서 u는 첫 번째 기호, v는 두 번째 기호에 대응한다. 이후 각 2‑그램에 대해 대표값 F(G)=Z·∏γ_k (Z=255, γ=0.9) 를 계산하고, 이 값을 선의 두께로 사용해 좌표들을 발음 순서대로 직선으로 연결한다. 결과적으로 128×128 픽셀 크기의 2차원 이미지가 생성되며, 이는 발음 구조를 시각화한 “음성 특징(PF)”이다. 넷째, 두 상표의 PF를 각각 빨강·초록 채널에 배치하고, 세 번째 채널은 0으로 채워 3채널 이미지 형태로 만든 뒤 CNN에 입력한다.
CNN 아키텍처는 Conv2D(5×5, 32) → MaxPool(2×2) → Conv2D(5×5, 64) → MaxPool(2×2) → Flatten → Fully Connected(256) → Fully Connected(2) → Softmax 로 구성된다. 활성화 함수는 ReLU, 최적화는 Adam, Dropout 비율은 0.5이며, TensorFlow 1.4 환경에서 구현하였다.
실험 데이터는 2010~2016년 한국 지식재산권정보서비스(KIPRIS)에서 추출한 12,553개의 음성 유사(거절) 상표 쌍과 34,020개의 비유사(승인) 상표 쌍으로 구성되었다. 데이터는 9:1 비율로 훈련·검증 셋으로 나누었으며, 검증 정확도는 0.927을 기록했다. 동일 데이터에 코사인 거리 기반 간단 알고리즘을 적용했을 때는 정확도 0.742에 그쳤다. 즉, 제안 방법은 기존 방식 대비 약 25%p 향상된 성능을 보였다. 또한, 시각화된 PF 이미지에서 유사한 발음의 경우 두 채널이 겹쳐 노란색 영역이 크게 나타나는 것을 확인할 수 있었다.
결론에서는 2‑그램 기반 PF 생성이 CNN과 결합될 때 음성 유사성 판단에 효과적임을 강조하고, 향후 다중‑그램, 가변‑길이 시퀀스 모델, Transformer 기반 음성 임베딩과의 비교, 그리고 사전 매핑 최적화 등을 통해 성능을 더욱 향상시킬 수 있음을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기