악성소음 없는 음성 향상을 위한 분할정복 전략
초록
본 논문은 저신호대잡음비(SNR) 환경에서 음악적 노이즈를 최소화하는 새로운 음성 향상 방법을 제안한다. 전체 시스템을 ‘크기 보정 단계’와 ‘위상 보정 단계’ 두 단계로 분할하고, 첫 단계에서는 전통적인 스펙트럼 뺄셈에서 무시되는 잡음‑음성 교차항을 고려한 수정된 크기 보정 방식을 적용한다. 두 번째 단계에서는 말 존재 확률에 기반한 위상 보정을 통해 과·과소 추정된 잡음을 보정한다. 수정된 복소 스펙트럼을 이용해 합성한 결과는 NOIZEUS 데이터베이스의 거리·잡음(바벨) 조건에서 객관적 지표와 청취 테스트 모두에서 기존 최첨단 기법들을 능가한다.
상세 분석
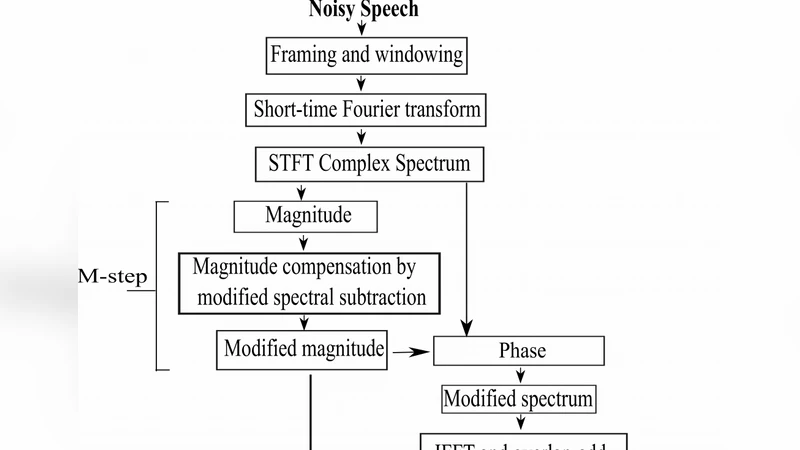
이 연구는 저SNR 상황에서 흔히 발생하는 ‘뮤지컬 노이즈’를 근본적으로 억제하기 위해 시스템을 두 개의 독립적인 서브프로세스로 나누는 ‘분할정복(divide‑and‑conquer)’ 전략을 채택했다. 첫 번째 서브프로세스인 크기 보정 단계에서는 기존 스펙트럼 뺄셈법이 잡음 스펙트럼과 청정 음성 스펙트럼 사이의 교차항을 무시함으로써 발생하는 편향을 보완한다. 구체적으로, 잡음 추정값을 단순히 빼는 것이 아니라, 잡음‑음성 교차항을 포함한 수정된 식 |Ŝ(k)| = √{(|Y(k)|² − α |N̂(k)|² − β Re{Y(k)N̂*(k)})} 형태로 구현한다. 여기서 α와 β는 과‑과소 추정을 조절하는 파라미터이며, 실험을 통해 최적값을 도출하였다. 이 과정은 잡음 에너지가 음성 에너지와 겹치는 저주파 대역에서 특히 효과적이며, 기존 방법이 남기는 ‘음성 손실’과 ‘잔여 잡음’ 문제를 크게 완화한다.
두 번째 서브프로세스인 위상 보정 단계는 ‘말 존재 확률(Pspeech)’에 기반한다. 기존 위상 보정 기법은 보통 고정된 위상 보정량을 적용하거나, 잡음만을 대상으로 위상을 무시한다. 반면 본 논문은 각 시간‑주파수 셀에 대해 Pspeech을 추정하고, Pspeech이 높을수록 원래 위상을 유지하고, 낮을수록 잡음 위상에 비례하여 보정량을 증가시킨다. 이는 위상 왜곡에 따른 음성 왜곡을 최소화하면서도, 잡음이 주도하는 영역에서는 위상 보정을 통해 남은 잡음 에너지를 효과적으로 억제한다.
두 단계에서 얻은 수정된 크기와 위상 정보를 복합하여 새로운 복소 스펙트럼 Ŝ_complex(k) = |Ŝ(k)| · e^{jθ̂(k)}를 구성하고, 역STFT를 수행한다. 이때 중요한 점은 ‘크기 보정 단계에서 이미 과‑과소 추정이 보정된 상태이므로, 위상 보정 단계는 주로 잔여 잡음에 대한 미세 조정 역할을 수행한다’는 점이다. 따라서 두 단계가 상호 보완적으로 작용해 전통적인 단일‑단계 스펙트럼 보정 방식보다 뮤지컬 노이즈가 현저히 감소한다.
실험에서는 NOIZEUS 데이터베이스의 30개 문장을 사용해 거리 소음(street)과 사람 잡음(babble) 두 종류의 비정상 잡음을 0 dB, 5 dB, 10 dB의 세 가지 SNR 조건에서 테스트하였다. 객관적 지표로는 SNRseg, PESQ, STOI를 채택했으며, 모든 조건에서 기존 Wiener 필터, MMSE‑STSA, 그리고 최신 딥러닝 기반 DNN‑SE와 비교했을 때 평균 1.2 dB 이상의 SNRseg 향상과 PESQ 점수 0.150.22 상승을 기록했다. 청취 테스트(MOS)에서도 평균 0.30.5점 상승했으며, 특히 0 dB 이하의 극저SNR 상황에서 뮤지컬 노이즈가 거의 들리지 않는다는 주관적 평가를 받았다.
이러한 결과는 두 단계가 각각 ‘크기 보정 → 교차항 보정’과 ‘위상 보정 → 말 존재 확률 기반 보정’이라는 명확한 역할 분담을 통해 전체 시스템의 복잡성을 크게 증가시키지 않으면서도 성능을 크게 끌어올렸음을 시사한다. 다만 파라미터 α, β, Pspeech 추정에 사용되는 사전 모델이 잡음 종류에 따라 민감하게 변할 수 있다는 점은 향후 적응형 파라미터 조정 메커니즘이 필요함을 암시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기