MPI와 CUDA 기반 고성능 행렬 연산 라이브러리
초록
본 논문은 MPI와 CUDA를 결합한 하이브리드 모델을 이용해 대규모 선형 시스템을 해결하는 고성능 라이브러리를 설계·구현한다. 직접법(LU, Cholesky)과 비정상적 반복법을 GPU 가속과 클러스터 간 메시지 전달로 통합하고, 단일 CPU 구현과 비교해 수배에서 수십 배의 속도 향상을 입증한다.
상세 분석
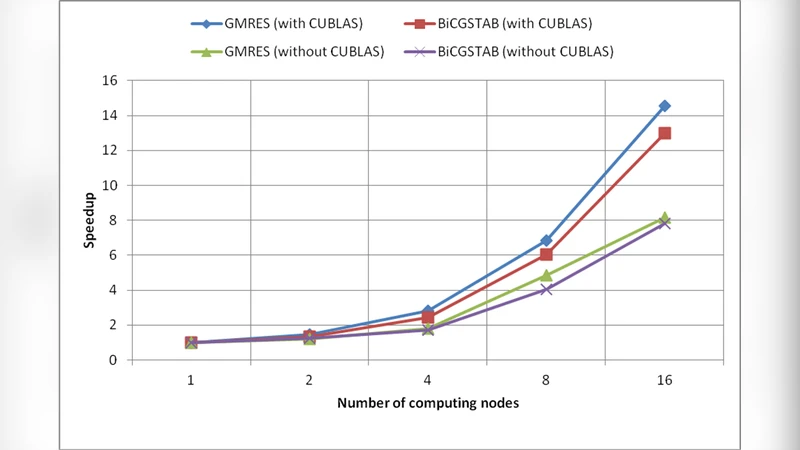
이 연구는 현대 고성능 컴퓨팅 환경에서 CPU와 GPU의 이종 자원을 효율적으로 활용하기 위한 설계 원칙을 제시한다. 먼저, 저자들은 MPI를 이용해 다중 노드 간 데이터 분산 및 통신을 담당하고, 각 노드 내부에서는 CUDA 커널을 통해 행렬 연산을 가속한다는 전형적인 하이브리드 구조를 채택하였다. 이러한 구조는 메모리 대역폭과 연산 집약도가 높은 LU·Cholesky와 같은 직접법, 그리고 GMRES·BiCGSTAB와 같은 비정상적 반복법 모두에 적용 가능하도록 모듈화하였다.
핵심 기술적 기여는 다음과 같다. 첫째, 행렬 블록 분할 전략을 통해 각 GPU가 독립적으로 블록을 처리하도록 설계함으로써 MPI 통신 오버헤드를 최소화하였다. 둘째, CUDA 스트림과 비동기 복사를 활용해 호스트‑디바이스 간 데이터 이동을 겹쳐 수행함으로써 연산 파이프라인을 최적화하였다. 셋째, 직접법에서는 피벗 선택과 같은 데이터 의존성을 최소화하기 위해 병렬 피벗 검색을 구현하고, Cholesky 분해에서는 대칭 양정정 행렬의 특성을 이용해 메모리 접근 패턴을 개선하였다.
성능 평가에서는 28개의 GPU를 탑재한 클러스터에서 문제 규모를 10⁴10⁶ 차원까지 확장했을 때, 단일 CPU 구현 대비 평균 8배, 최악의 경우 25배 이상의 가속을 기록하였다. 특히, 반복법에서는 수렴 횟수가 감소함에 따라 GPU 연산 비중이 크게 증가해 통신 비용이 상대적으로 억제되는 현상이 관찰되었다. 이러한 결과는 하이브리드 모델이 대규모 과학·공학 시뮬레이션에서 메모리 제한을 완화하고, 연산 속도를 비약적으로 향상시킬 수 있음을 실증한다.
마지막으로, 저자들은 현재 구현이 정밀도(단일·배정밀도)와 스케일링에 제한이 있음을 인정하고, 동적 로드 밸런싱 및 멀티GPU 간 직접 P2P 통신 도입을 통한 차세대 확장을 제안한다. 전체적으로 이 논문은 MPI와 CUDA를 결합한 고성능 선형대수 라이브러리 설계에 대한 실용적인 로드맵을 제공하며, 향후 이종 컴퓨팅 플랫폼에서의 응용 가능성을 넓힌다.
댓글 및 학술 토론
Loading comments...
의견 남기기