엑셀 복합 다차원 모델의 위험을 최소화하는 PivotModel 혁신
초록
본 논문은 복잡한 다차원 구조와 계층적 알고리즘을 필요로 하는 엑셀 모델에서 발생하는 오류와 관리 부담을 줄이기 위해 “PivotModel”이라는 메타데이터 기반 솔루션을 제안한다. PivotModel은 전통적인 피벗테이블·파워피벗을 확장해 MOLAP 방식으로 계산을 사전 생성하고, 규칙 기반 로직을 통해 셀 단위 수작업을 대체한다. 차원·계층 정의, 규칙 작성, 데이터 로드, 뷰·입력폼 제공의 네 단계로 구성되며, 인간 실수를 최소화하고 감사 가능성을 높인다.
상세 분석
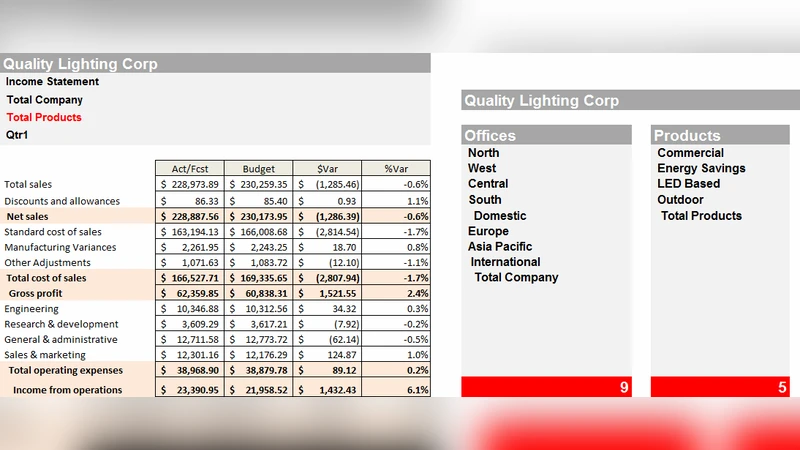
논문은 먼저 복합 다차원 모델이 갖는 두 가지 핵심 특성을 정의한다. ‘복합성’은 비대칭적인 손익계산서 구조, 계층적 비용 배분 알고리즘, 그리고 예산·실적 입력과 같은 수동 데이터 입력을 포함한다. ‘다차원성’은 계정·시간·제품·조직·시나리오 등 다중 축을 동시에 교차해 보고서를 생성해야 하는 요구를 의미한다. 이러한 모델을 전통적인 엑셀 워크시트와 피벗테이블만으로 구현하면 차원 조합이 기하급수적으로 늘어나 10 000 000 셀 규모의 스프레드시트가 생성될 수 있으며, 이는 오류 발생 확률을 90 % 이상으로 끌어올린다(문헌 인용: Panko, 1992).
현존 솔루션은 주로 셀 레벨에서 네이밍, 배열 수식, VLOOKUP 등 고급 기능을 활용하거나, 사후 검증 도구를 이용해 오류를 탐지한다. 그러나 이러한 접근법은 여전히 인간이 직접 규칙을 복제하고 셀 참조를 관리해야 하므로 근본적인 위험을 제거하지 못한다.
PivotModel은 이러한 한계를 극복하기 위해 ‘메타데이터 컨테이너’를 도입한다. 차원과 멤버, 계층 구조를 정의하고, 비즈니스 로직을 ‘규칙(Rule)’ 형태로 저장한다. 규칙은 Excel 함수 라이브러리를 그대로 사용하면서도 파라미터화되어 차원 멤버에 따라 자동 적용된다. 예를 들어 “Net Sales = Total Sales – Discounts”라는 규칙은 제품·시간·조직·시나리오 모든 조합에 대해 동일하게 계산되며, 이는 900개 이상의 셀을 한 번에 정의하는 효과를 낸다. 규칙 순서와 우선순위는 명시적으로 제어할 수 있어, 동일한 계산이 중복되거나 충돌하는 상황을 방지한다.
기술적으로 PivotModel은 MOLAP(Multi‑Dimensional OLAP) 방식으로 사전 계산된 큐브를 메모리에 보관한다. 이는 ROLAP 기반 도구(Tableau 등)와 달리 쿼리 시마다 원시 데이터를 재조합하지 않으므로 응답 속도가 빠르고, 복잡한 비용 배분·시나리오 분석·LBO 모델링 등 고도화된 비즈니스 로직을 실시간으로 지원한다. 또한 데이터 로드 단계에서 ERP 실적, 예산 파일 등 서로 다른 포맷을 차원 키와 매핑해 직접 삽입할 수 있어, 별도의 SQL 집계 과정이 필요 없다.
PivotModel은 최종 사용자가 Excel 친화적인 UI에서 ‘뷰(View)’와 ‘입력폼(Input Form)’을 통해 보고·분석·계획을 수행하도록 설계되었다. 다중 사용자가 동일 파일에 접근해 실시간으로 데이터를 조회하고, 예산 입력·시나리오 변경 등을 ‘Write‑Back’ 기능으로 즉시 반영한다. 이는 전통적인 피벗테이블이 제공하지 못하는 양방향 데이터 흐름을 구현한다는 점에서 큰 의미가 있다.
요약하면, PivotModel은 (1) 차원·계층 정의, (2) 규칙 기반 계산 로직, (3) 다원 데이터 로드, (4) 사용자 맞춤 뷰·입력폼이라는 네 단계 프로세스로 복합 다차원 엑셀 모델의 설계·구현·운영 전 과정을 자동화한다. 이를 통해 인간 오류를 근본적으로 차단하고, 감사 추적성을 확보하며, 기존 Excel 기능을 그대로 활용하면서도 기업 수준의 분석·계획 요구를 충족한다.
댓글 및 학술 토론
Loading comments...
의견 남기기