성격 인식 정확도 향상을 위한 성별·모국어 기반 모델 동질화와 정규화 전략
본 연구는 영어 발화에서 빅파이브 성격 특성을 3단계(높음·보통·낮음)로 분류하는 기존 37‑44% 정확도를 개선하고자, 화자 성별과 모국어(L1) 차이를 고려한 동질화 모델과 정규화 기법을 비교한다. 전체 데이터를 사용한 베이스라인 대비, 성별·L1 별로 데이터를 분할한 동질화 모델이 대부분의 특성에서 성능을 높였으며, 특히 여성·영어 화자와 중국어 화자 그룹에서 큰 향상이 관찰되었다. 정규화 방식은 전반적으로 큰 효과를 보이지 못했다.
저자: Guozhen An, Rivka Levitan
**연구 배경 및 목적**
성격은 개인의 사고·감정·행동 패턴을 설명하는 핵심 변수이며, 빅파이브(오픈니스, 성실성, 외향성, 친화성, 신경증) 모델이 널리 사용된다. 최근 자동 성격 인식 연구는 음성·텍스트 피처를 활용해 관찰자 평가를 예측했지만, 자기보고식 성격 점수는 더 어려운 과제로 남아 있다. 특히, 화자의 성별과 모국어(L1)에 따라 음성·언어 특성이 크게 달라지므로, 이질성을 무시한 모델은 성능 저하를 초래한다. 본 논문은 이러한 이질성을 완화하기 위해 **동질화**와 **정규화** 두 전략을 비교한다.
**데이터셋**
- 173쌍(346명)의 화자, 남·여, 미국식 영어(SAE)와 중국어(MC) 모국어 구분
- 총 125시간, 약 30,000 턴(평균 3.77초)
- 각 화자는 NEO‑FFI 설문을 통해 5개 성격 차원 점수를 제공
- 인터뷰는 ‘가짜 이력서’ 과제에서 거짓·진실 발화를 포함, 베이스라인 발화 3‑4분을 별도 수집해 정규화에 활용
- 전사본은 AMT를 통해 3인 합성 후 70% 이하 일치 시 수동 교정
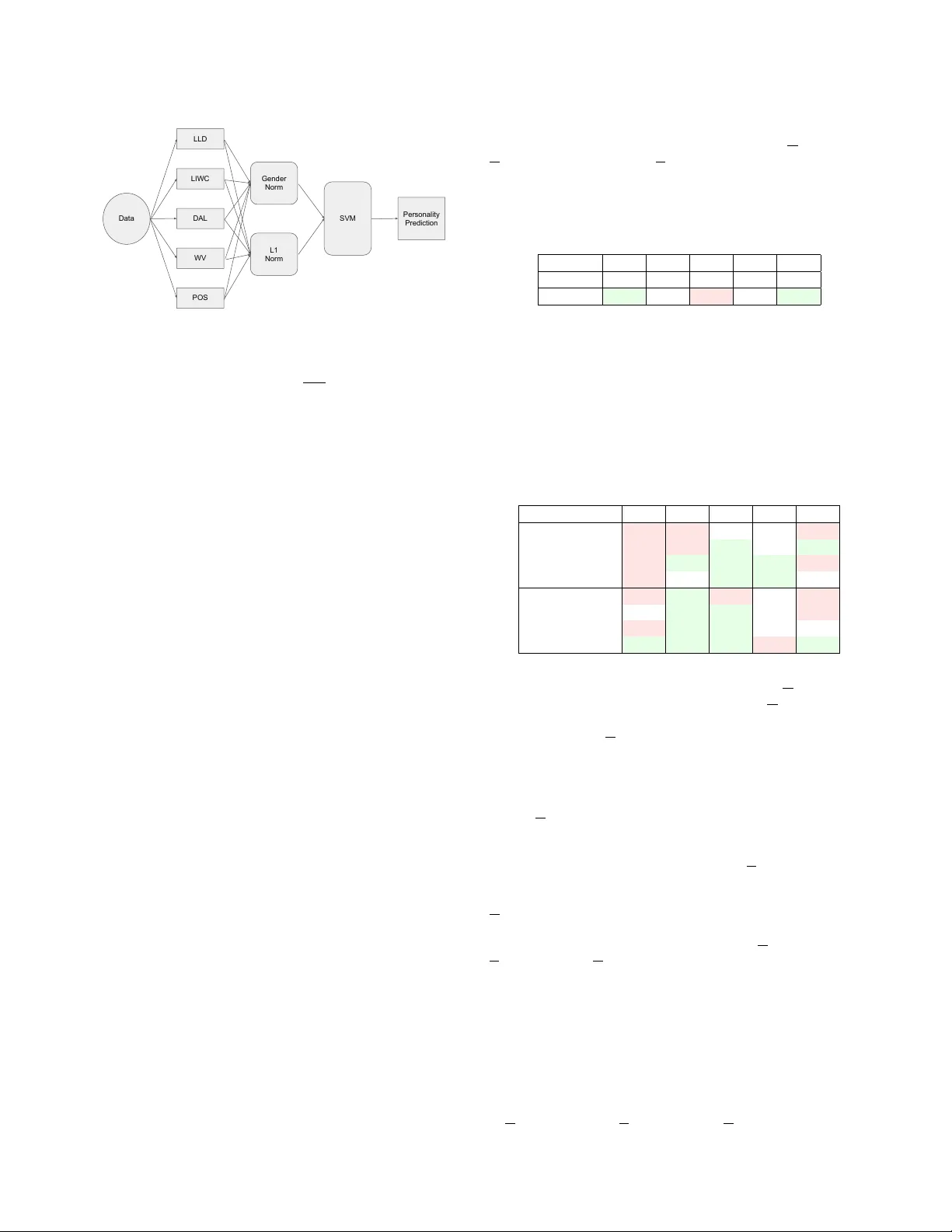
**피처 구성**
1. **LLD**: 저수준 음성·프로소디 피처
2. **LIWC**: 심리언어 카테고리
3. **DAL**: 감정 어휘(쾌감·활성·이미지) 점수
4. **WV**: 사전학습 300‑차원 워드 벡터 평균
5. **POS**: 45가지 품사 빈도
모든 피처를 결합해 SVM(Weka) 분류기를 학습한다. 라벨은 인구통계학적 기준에 따라 HI, ME, LO 세 단계로 구분한다. 훈련 시 클래스 불균형을 해소하기 위해 오버샘플링을 적용한다.
**동질화 모델**
- 성별(남, 여) 혹은 L1(SAE, MC) 별로 데이터를 분할, 각 서브셋에 독립 모델 학습
- 테스트 시 해당 화자의 실제 라벨(성별·L1)과 매칭된 모델 사용
- 결과:
- Openness: 전체 베이스라인 0.39 > 대부분 동질화 모델 (최고 0.48, 여성·영어)
- Conscientiousness: L1 동질화(중국어 0.37)·성별·L1 복합 모델(0.47) 등에서 개선
- Extraversion: 베이스라인 이하였으나 여성·중국어(0.43), 여성·영어(0.48) 등에서 유의미한 상승
- Agreeableness: L1 동질화(중국어 0.39)에서 베이스라인 초과
- Neuroticism: 여성 모델(0.43)·여성·영어(0.40)에서 큰 향상
남성 전용 모델은 대부분 베이스라인보다 낮았으며, 이는 데이터 감소와 남성 발화의 변동성이 복합적으로 작용했을 가능성을 시사한다. 특히, 중국어 L1 모델은 전체 데이터의 30‑39%만 사용했음에도 불구하고 여러 차원에서 베이스라인을 능가했으며, 이는 문화적 차이가 성격 표현에 중요한 역할을 함을 뒷받침한다.
**정규화 모델**
- **화자 정규화**: 각 화자별 평균·표준편차로 z‑score 변환
- **성별 정규화**: 성별별 통계값 사용
- **L1 정규화**: L1 별 통계값 사용
결과:
- 화자 정규화는 모든 차원에서 0.33(우연 수준)으로 성능이 정체
- 성별 정규화는 Openness 0.38 정도의 소폭 개선만 나타남
- L1 정규화는 Conscientiousness 0.36, Extraversion 0.32 등 미미한 상승
정규화는 음성·언어 차이를 보정하지만, 문화·성별에 따른 성격 표현 차이를 반영하지 못한다는 한계가 명확히 드러났다.
**논의 및 시사점**
1. **동질화의 효용**: 성별·L1 별로 모델을 분리하면 훈련 데이터가 감소하지만, 동일 집단 내 일관된 특성으로 인해 전반적인 성능이 향상된다. 특히 여성·영어와 중국어 L1 그룹에서 큰 효과가 관찰돼, 향후 다문화 음성 데이터 활용 시 사전 군집화가 필요함을 강조한다.
2. **정규화의 한계**: 단순 통계적 보정은 음성 피치·속도 차이는 줄이지만, 문화적·사회적 배경이 성격 표현에 미치는 복합적 영향을 제거하지 못한다. 따라서 정규화만으로는 충분하지 않다.
3. **데이터 불균형 문제**: 중국어 L1 데이터가 전체의 30‑39%에 불과함에도 불구하고 동질화 모델이 우수한 성능을 보인 점은, 서로 다른 L1 데이터가 상호 간에 방해 효과를 낼 수 있음을 시사한다.
4. **실용적 적용**: 실제 시스템에서는 성별·L1 라벨이 사전 제공되지 않을 수 있다. 논문은 성별 예측 정확도 95%, L1 예측 80% 수준을 인용해, 자동 라벨링을 통해 동질화 모델을 적용할 수 있음을 제시한다.
5. **향후 연구**: (i) 다중 특성(성별·L1·연령 등) 복합 동질화, (ii) 딥러닝 기반 피처 자동 학습 및 군집화, (iii) 자기보고식 성격 점수와 관찰자 평가를 동시에 활용한 멀티태스크 학습 등.
**결론**
성별·모국어에 따른 음성·언어 차이를 고려한 동질화 모델이 기존 이질성 기반 베이스라인보다 대부분의 빅파이브 차원에서 높은 정확도를 달성했으며, 정규화는 제한적인 개선만을 제공한다. 따라서 다문화·다성별 음성 데이터 기반 성격 인식 시스템을 설계할 때는 사전 군집화와 특화된 모델 학습이 핵심 전략임을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기