딥 액티브 러닝을 활용한 명명된 개체 인식 효율화
초록
본 논문은 경량화된 CNN‑CNN‑LSTM 구조와 불확실도 기반 액티브 러닝을 결합해, 기존 최첨단 NER 모델의 성능을 유지하면서도 학습 데이터 양을 25 % 수준으로 크게 줄이는 방법을 제시한다. 모델은 문자‑CNN, 단어‑CNN, LSTM 태그 디코더로 구성되어 빠른 재학습이 가능하며, 길이 정규화 로그 확률(MNLP)과 최소 신뢰도(LC) 등 세 가지 샘플 선택 기준을 실험한다. OntoNotes 영어·중국어 데이터셋에서 99 % 수준의 F1 점수를 달성함으로써, 딥러닝 기반 NER에 액티브 러닝을 실용적으로 적용할 수 있음을 입증한다.
상세 분석
이 연구는 두 가지 핵심 문제를 동시에 해결한다. 첫째, 기존 딥러닝 기반 NER 모델은 높은 정확도를 제공하지만, 대규모 라벨링 비용이 큰 장애물이다. 둘째, 액티브 러닝은 라벨링 비용을 절감할 수 있으나, 매 라운드마다 전체 모델을 재학습해야 하는 높은 연산 비용이 실용성을 저해한다. 저자들은 이러한 문제를 완화하기 위해 ‘CNN‑CNN‑LSTM’이라는 경량 아키텍처를 설계하였다. 문자 수준에서는 다중 레이어 CNN에 ReLU와 dropout, residual 연결을 적용해 고정 길이의 문자 특징을 추출하고, 이를 단어 임베딩과 결합한다. 단어 수준 인코더 역시 얕은 CNN을 사용해 주변 단어 컨텍스트를 효율적으로 포착한다. 마지막 태그 디코더는 CRF 대신 LSTM 기반 시퀀스 디코더를 채택했으며, 이는 전역 정규화 비용을 회피하면서도 greedy decoding으로 CRF 수준의 성능을 유지한다.
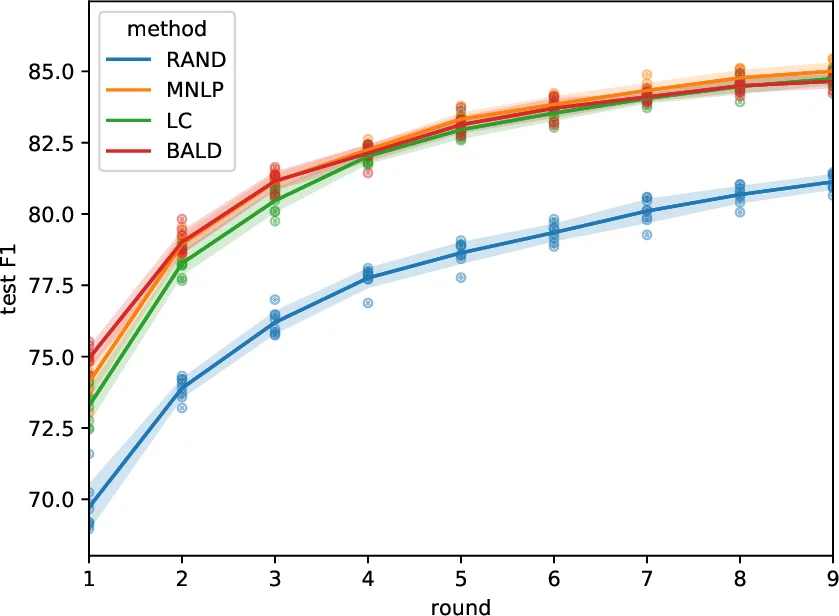
액티브 러닝 부분에서는 불확실도 기반 샘플링을 중심으로 세 가지 전략을 제안한다. (1) Least Confidence(LC)는 모델이 가장 높은 확률을 부여한 태그 시퀀스의 확률을 역전시켜 불확실도가 큰 문장을 선택한다. (2) Maximum Normalized Log‑Probability(MNLP)는 LC가 긴 문장을 과도히 선택하는 문제를 보완하기 위해 로그 확률을 문장 길이로 정규화한다. (3) Bayesian Active Learning by Disagreement(BALD)는 dropout을 이용한 MC‑Dropout 방식으로 예측 분산을 측정한다. 실험에서는 LC와 MNLP가 특히 높은 효율을 보였으며, BALD와 비교했을 때 계산 비용이 현저히 낮았다.
학습 과정은 전통적인 ‘재학습 후 라벨링’ 방식 대신, 새로 얻은 라벨을 기존 데이터와 혼합해 소수 에폭만 추가 학습하는 인크리멘털 방식을 채택했다. 이는 전체 재학습에 비해 GPU 시간과 메모리 사용량을 크게 절감한다. 실험 결과, OntoNotes‑5.0 영어 데이터셋에서 전체 라벨의 24.9 %만 사용해도 기존 최첨단 모델이 달성한 F1 점수의 99 %를 복원했으며, 중국어 데이터셋에서도 30.1 % 라벨로 동일 수준을 유지했다. 또한, 제안된 경량 모델은 기존 LSTM‑CRF 기반 모델 대비 학습 속도가 2~3배 빠르고, 메모리 요구량도 크게 낮았다.
이 논문의 주요 기여는 (1) CNN‑CNN‑LSTM이라는 효율적인 NER 아키텍처 설계, (2) 길이 정규화 로그 확률을 이용한 실용적인 불확실도 샘플링 기법, (3) 인크리멘털 학습을 통한 액티브 러닝 비용 최소화이다. 한계점으로는 현재 실험이 영어·중국어 두 언어에 국한되어 있어, 다른 언어·도메인에 대한 일반화 검증이 필요하고, LSTM 디코더의 greedy decoding이 복잡한 구조적 제약을 완전히 반영하지 못한다는 점을 들 수 있다. 향후 연구에서는 다중 언어 확장, CRF와 LSTM 디코더의 하이브리드, 그리고 더 정교한 불확실도 추정 방법을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기