UMDA 런타임 혁신: 반집중성으로 O(n·λ) 달성
초록
**
본 논문은 Univariate Marginal Distribution Algorithm(UMDA)의 OneMax 최적화에 대해, 모집단 크기 λ와 µ에 대한 제한 하에 기존 O(n·λ·log λ) 상한을 제거하고 O(n·λ) 상한을 증명한다. 핵심은 레벨 기반 정리와 포아송‑이항 분포의 반집중성(anti‑concentration) 부등식을 결합한 새로운 분석 기법이다. λ=O(log n)인 경우 Θ(n·log n) 런타임을 얻어 전통적 (1+1) EA와 동일한 효율을 보인다.
**
상세 분석
**
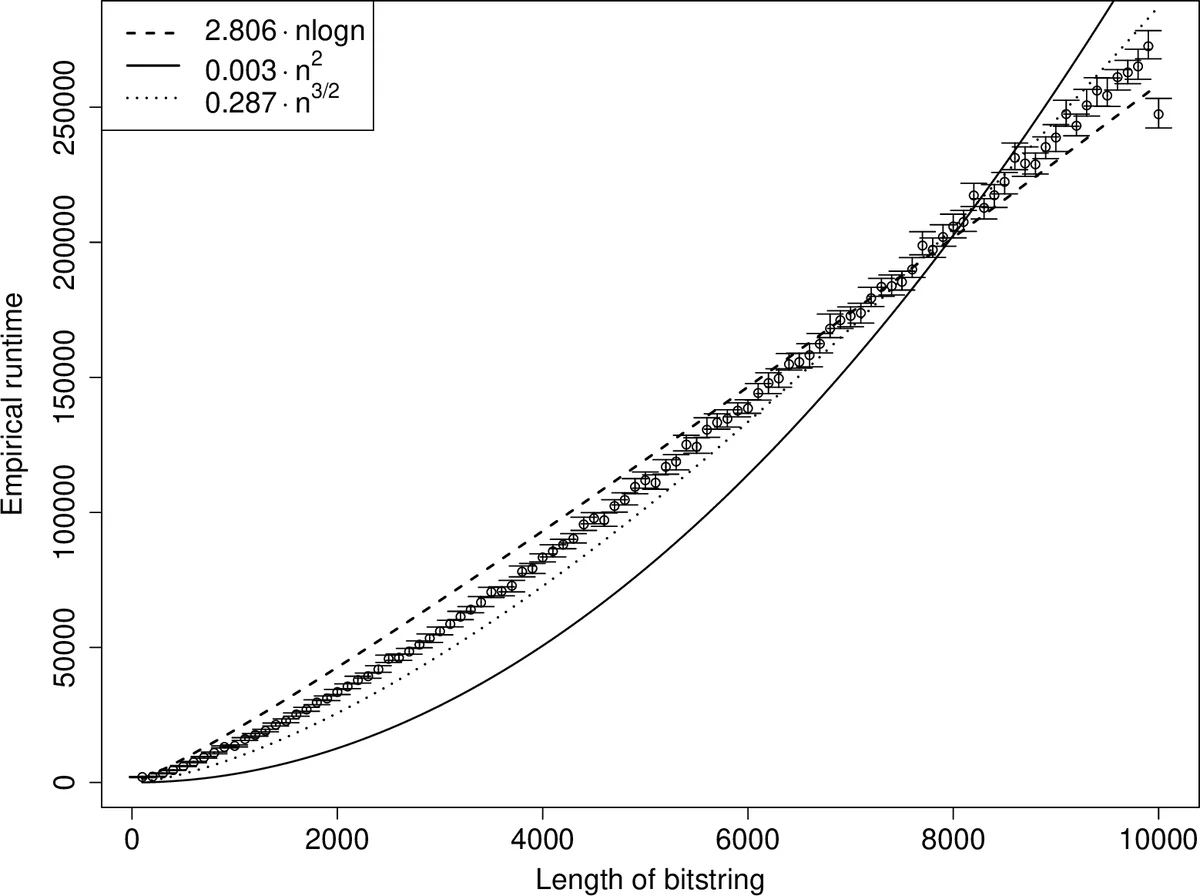
본 연구는 UMDA가 OneMax 문제에서 보이는 수렴 속도를 정확히 파악하기 위해 두 가지 강력한 도구를 결합한다. 첫 번째는 레벨 기반 정리(level‑based theorem)로, 알고리즘을 “레벨”이라 불리는 상태 집합으로 분할하고, 각 레벨에서 상위 레벨로 전이될 최소 확률(z_j)과 전이 가속도(δ)를 확보하면 전체 기대 최적화 시간에 대한 명시적 상한을 얻을 수 있다. 기존 연구에서는 이 전이 확률을 보수적으로 추정해 O(n·λ·log λ)라는 로그 항을 남겼다.
두 번째 핵심은 포아송‑이항 분포의 반집중성(anti‑concentration) 부등식이다. UMDA는 각 비트에 대해 독립적인 베르누이 확률 p_t(i)를 유지하고, 다음 세대의 개체는 이 확률들의 곱으로 샘플링된다. 따라서 한 개체의 1‑비트 수 Y는 p_t(i)들의 합으로 표현되는 포아송‑이항 변수이며, 그 분포가 특정 값에 과도하게 집중되지 않음을 보이는 것이 전이 확률을 강화하는 데 필수적이다. 논문은 정밀한 상한 σ_n·Pr(Y=y) ≤ η (η≈0.4688)와 Feige의 부등식 Pr(Y ≥ μ−Δ) ≥ min{1/13, Δ/(1+Δ)}을 활용해, 현재 모집단에 충분히 많은 “좋은” 개체가 존재할 때 다음 세대가 더 높은 레벨에 도달할 확률을 기존보다 크게 잡는다.
이러한 두 도구를 결합하면, µ와 λ 사이에 c·log n ≤ µ = O(√n) 및 λ = Ω(µ) 라는 제한만 만족하면, (G1)·(G2)·(G3) 조건을 모두 충족시켜 레벨 기반 정리의 기대 시간 상한을
\
댓글 및 학술 토론
Loading comments...
의견 남기기