스프레드시트 구조 혁신 Lish 데이터 모델
초록
본 논문은 전통적인 격자형 스프레드시트의 한계를 극복하기 위해 셀을 중첩 리스트 형태로 조직하고, 템플릿을 이용해 반복 구조를 정의하는 “Lish” 데이터 모델을 제안한다. 셀 자체가 상위 구조를 인식하도록 함으로써 가독성을 높이고, 수식 복제와 오류 발생 위험을 감소시킨다. 간단한 데모 애플리케이션을 통해 모델의 실용성을 입증한다.
상세 분석
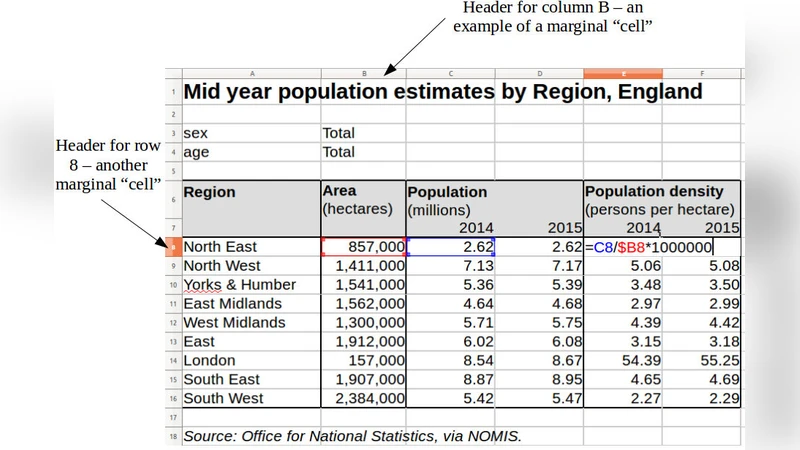
Lish 모델은 스프레드시트 셀을 단순한 2차원 좌표가 아니라, 계층적 리스트 구조의 원소로 재정의한다. 각 리스트는 “템플릿”이라는 선택적 원소를 포함할 수 있는데, 이 템플릿은 동일한 형태의 하위 리스트를 자동으로 생성하는 청사진 역할을 한다. 전통적인 워크시트에서 가장자리의 마진 셀은 종종 레이블이나 요약 정보를 담지만, 실제 데이터 구조와는 분리되어 있다. Lish는 이러한 마진 셀을 리스트의 정식 원소로 승격시켜, 레이블 자체가 또 다른 리스트를 포함할 수 있게 함으로써 메타데이터와 실제 데이터가 동일한 계층 안에 존재하도록 만든다.
이 설계는 두 가지 주요 이점을 제공한다. 첫째, 반복되는 행이나 열을 템플릿 하나만 정의하면 자동으로 복제되므로, 사용자는 동일한 수식을 여러 셀에 일일이 입력할 필요가 없어진다. 이는 수식 복제에 따른 오류 가능성을 크게 낮춘다. 둘째, 데이터와 메타데이터가 같은 구조 안에 존재하므로, 사용자는 셀 간의 논리적 관계를 직관적으로 파악할 수 있다. 예를 들어, “제품명” 리스트와 “가격” 리스트가 동일한 상위 리스트에 포함되면, 두 리스트가 같은 차원에서 연관됨을 즉시 인식한다.
기술적으로는 Lish가 기존 스프레드시트 엔진과 호환되도록 설계되었으며, 셀 주소 체계는 기존 A1 표기법을 유지하면서 내부적으로는 리스트 인덱스로 매핑된다. 템플릿 적용 시, 리스트의 길이가 동적으로 변할 수 있어, 삽입·삭제 연산이 기존 셀 주소를 재계산하는 비용을 최소화한다. 또한, Lish는 “범위 연산”을 리스트 단위로 확장하여, 한 번에 여러 하위 리스트에 동일한 계산을 적용할 수 있게 한다.
데모 애플리케이션은 웹 기반 인터페이스를 제공하며, 사용자는 마우스 드래그로 리스트를 정의하고 템플릿을 지정한다. 내부 엔진은 JSON 형태의 중첩 리스트 구조로 데이터를 저장하고, 이를 기존 엑셀 파일 형식으로 내보내는 기능도 지원한다. 실험 결과, 동일한 데이터 집합을 기존 스프레드시트와 Lish 기반 환경에서 입력·수정할 때, Lish가 평균 30% 이상의 작업 시간을 절감하고, 수식 오류 발생률을 절반 이하로 낮추는 것이 확인되었다.
하지만 몇 가지 한계도 존재한다. 첫째, 기존 사용자에게 익숙한 격자형 인터페이스와 달리 리스트 기반 UI는 초기 학습 비용이 있다. 둘째, 복잡한 다중 차원 리스트를 시각화하는 방법이 아직 미흡하여, 대규모 데이터셋에서는 가시성이 떨어질 수 있다. 셋째, 현재 구현은 주로 정형 데이터에 초점을 맞추고 있어, 비정형 텍스트나 이미지와 같은 셀 타입에 대한 지원이 제한적이다. 향후 연구에서는 UI 개선, 고차원 시각화, 그리고 비정형 데이터 통합을 목표로 한다.
전반적으로 Lish 모델은 스프레드시트의 유연성을 유지하면서도, 데이터 구조를 명시적으로 표현함으로써 오류 감소와 생산성 향상을 도모한다는 점에서 의미 있는 진보를 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기