알렉사 프라이스가 이끈 대화형 AI 혁신
초록
알렉사 프라이스는 2.5 백만 달러 규모의 대학 경연으로, 16개 팀이 20분 이상 지속되는 자연스러운 사회적 대화를 목표로 소셜봇을 개발하도록 유도했다. 대회는 실시간 사용자 피드백, 대규모 대화 데이터, 맞춤형 ASR·NLU·대화 관리 프레임워크 등을 제공해 학계와 산업계가 협업할 수 있는 환경을 조성했으며, 각 팀은 최신 자연어 이해·맥락 모델링·응답 생성 기술을 적용해 성능을 지속적으로 개선했다. 알렉사 팀은 음성 인식, 주제 추적, 대화 평가, 트래픽 관리 등 인프라를 강화해 대규모 실사용 환경을 지원했고, 결과적으로 대화형 AI 연구에 필요한 데이터와 베이스라인을 제공하였다.
상세 분석
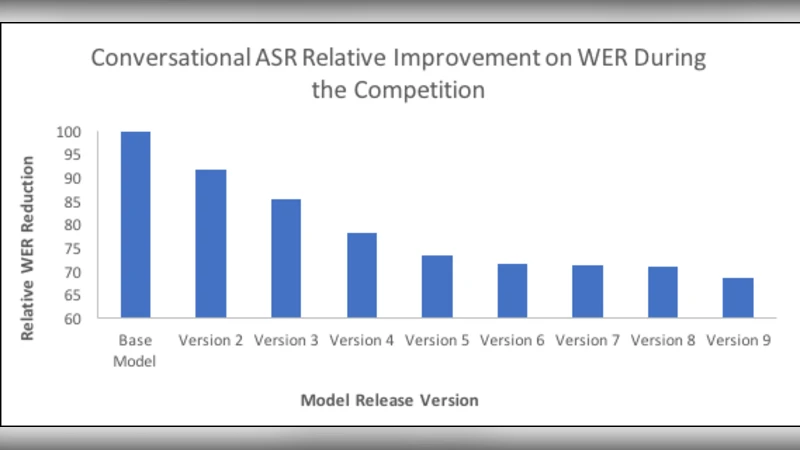
본 논문은 알렉사 프라이스 대회의 설계와 실행 과정을 기술함으로써 대화형 AI 연구에 필요한 핵심 인프라와 평가 메커니즘을 제시한다. 첫째, 대회는 실제 사용자와의 실시간 인터랙션을 통해 수집된 수십만 시간의 대화 로그와 별점·자유형 피드백을 제공함으로써, 기존 연구에서 흔히 겪는 데이터 부족 문제를 해결한다. 둘째, 음성 입력을 텍스트로 변환하는 Conversational ASR은 장시간 자유형 대화를 위한 긴 인식 타임아웃과 오프라인 튜닝을 적용했으며, 토큰‑레벨 confidence 정보를 공개해 NLU 모델의 오류 분석을 가능하게 했다. 셋째, NLU 파이프라인은 기본 ASK 제공 모델 외에 팀별 맞춤형 엔티티 추출·의도 분류·다중 턴 컨텍스트 추적을 허용했으며, 주제 트래킹 시스템은 실시간 뉴스 피드와 CAPC 데이터셋을 활용해 최신 이슈를 자동으로 감지한다. 넷째, 대화 관리 프레임워크는 ‘Links’라는 다단계 스킬 연동 방식을 도입해 사용자 호출 → 대화 시작 → 평가 수집까지의 흐름을 일관되게 제어했으며, 가동률 모니터링과 자동 오프라인 전환 로직을 통해 수백만 건의 트래픽에서도 서비스 안정성을 유지했다. 다섯째, 평가 메트릭은 단순 별점 외에 대화 길이, 턴 수, 주제 전환 빈도, 부적절 발언 필터링 성공률 등을 포함해 다차원적인 품질 측정을 가능하게 했다. 이러한 인프라와 데이터는 팀들이 최신 Transformer 기반 언어 모델, 강화학습 기반 정책 최적화, 지식 그래프 기반 응답 생성 등 다양한 연구 아이디어를 실험하고 빠르게 반복할 수 있는 기반을 제공한다. 마지막으로, 대회는 사용자 경험(UX) 설계 측면에서도 ‘알렉사, 대화하자’라는 직관적 호출어와 짧은 안내 멘트를 통해 사용자의 진입 장벽을 낮추고, 평가 단계에서 자유형 음성 피드백을 허용해 정량·정성 데이터를 동시에 확보했다. 종합적으로, 알렉사 프라이스는 대규모 실사용 환경에서 대화형 AI를 평가·개선할 수 있는 종합 플랫폼을 구축했으며, 이는 향후 장기 대화, 멀티도메인 이해, 개인화된 대화 시스템 연구에 중요한 벤치마크가 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기