데이터 획득의 근본 한계 샘플 복잡도와 질의 난이도 트레이드오프
이 논문은 Fountain 코드 기반의 패리티 질의를 이용해 k개의 이진 정보를 복구하는 과정에서, 평균 질의 난이도(한 질의당 평균 포함 비트 수)와 필요한 측정 수(샘플 복잡도) 사이의 근본적인 관계를 규명한다. 주요 결과는 평균 난이도 \(\bar d\)에 대해 샘플 복잡도가 \(n = \Theta\!\big(\max\{k,\;k\log k/\bar d\}\big)\) 로 정확히 결정된다는 것이다. 즉, 난이도가 상수 수준이면 \(n = …
저자: Hye Won Chung, Ji Oon Lee, Alfred O. Hero
본 논문은 “쿼리 기반 데이터 획득”이라는 프레임워크를 설정하고, 이와 연관된 정보 복구 문제를 Fountain 코드의 인코딩 규칙을 이용해 모델링한다. 목표는 k개의 이진 변수(정보 비트)를 패리티 측정( XOR)으로 복구하는 것이며, 각 측정은 임의의 비트 집합에 대한 XOR 결과로 정의된다. 이러한 측정은 무한히 생성할 수 있는 Fountain 코드의 출력 심볼에 해당한다.
**문제 설정 및 정의**
- 입력 벡터 \(x = (X_1,\dots,X_k)\)는 균등하게 무작위 선택된 이진 벡터이다.
- 각 출력 심볼 \(Y_i\)는 무작위 가중치 \(d\)를 분포 \(\Omega_d\)에서 샘플링하고, 그 가중치에 해당하는 입력 비트를 균등하게 선택해 XOR한 결과이다.
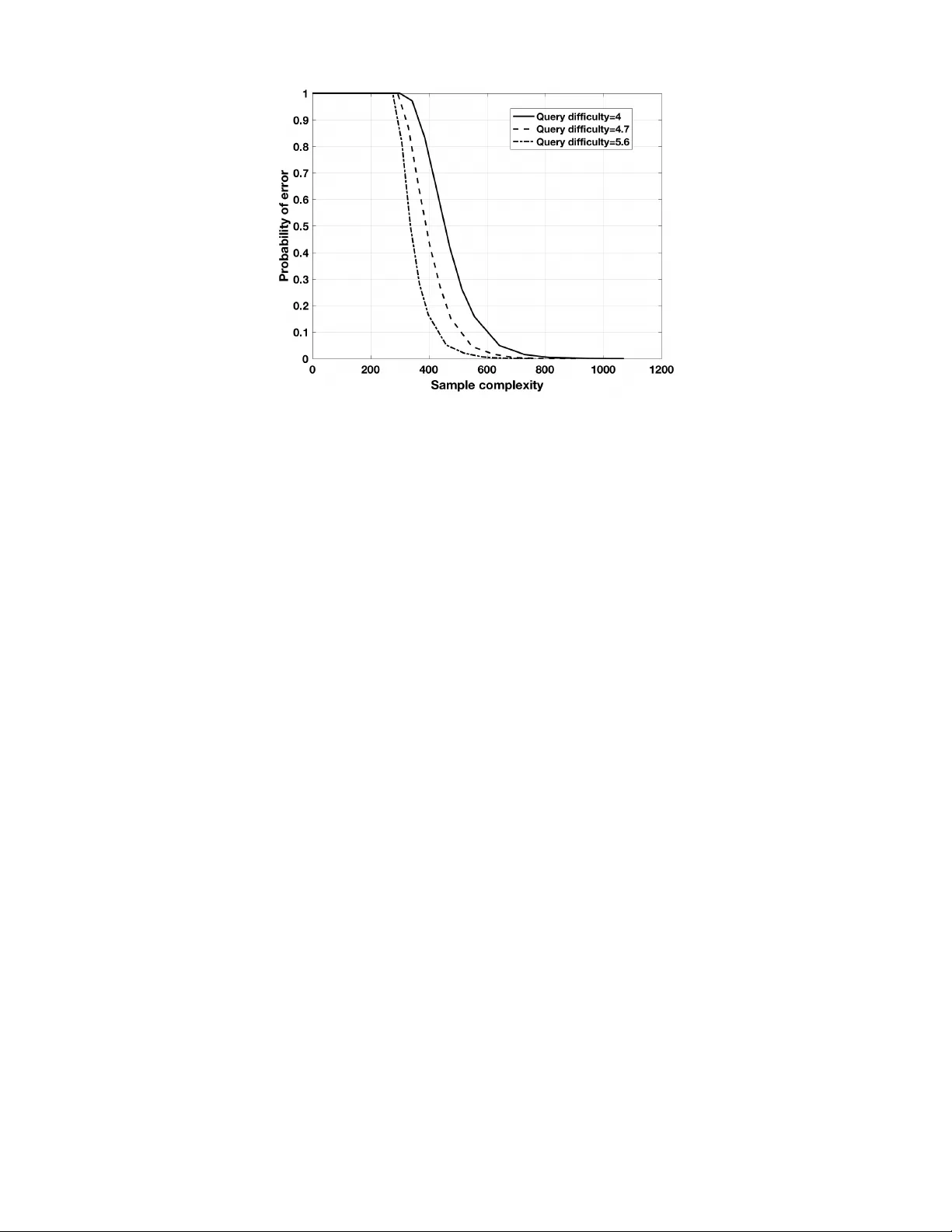
- 평균 가중치 \(\bar d = \sum_{d} d\Omega_d\) 를 ‘쿼리 난이도’라 부른다. 이는 한 질의당 평균적으로 몇 개의 입력 비트를 포함하는지를 나타낸다.
- 복구 성공 확률을 \(P_e^{(k)}\) 로 정의하고, \(P_e^{(k)}\to0\) (k→∞) 가 되도록 하는 최소 출력 수 n을 ‘샘플 복잡도’라 정의한다.
**주요 이론적 결과**
1. **하한 (Proposition 1)**
- 선형 시스템 해를 위해 최소 k개의 독립 방정식이 필요하므로 \(n\ge k\).
- 입력 노드가 고립될 확률을 고려하면 \(n\ge (c\,k\log k)/\bar d\) 가 필요함을 보인다.
- 따라서 전체 하한은 \(n\ge c_{\ell}\max\{k, k\log k/\bar d\}\).
2. **상한 (Theorem 1)**
- 이상 솔리톤 분포 \(\Omega_d\) (d=1일 때 1/D, 2≤d≤D일 때 \(1/
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기