FPGA 기반 엣지 컴퓨팅을 위한 자동화된 이진 CNN 압축 흐름
초록
본 논문은 TensorFlow에서 학습된 CNN 모델을 1‑bit 가중치와 2‑bit 활성화로 양자화하고, 자동으로 임베디드 C 코드와 FPGA 가속기를 생성하는 전체 파이프라인을 제시한다. Cyclone‑V SoC에 이진화된 YOLO‑v2를 구현해 모델 크기를 32배 축소하고, FPGA 가속을 통해 모바일 CPU 대비 최대 11.5배, 데스크톱 CPU 대비 1.8배 빠른 추론 속도를 달성하였다. 전체 흐름은 모델 파싱부터 FPGA 합성까지 약 1시간 내에 완료된다.
상세 분석
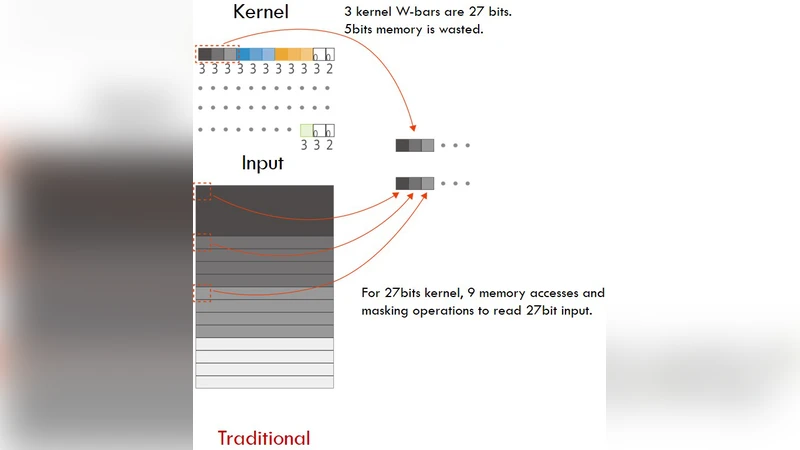
이 논문은 엣지 디바이스에서의 딥러닝 적용을 가로막는 전력·비용·메모리 한계를 극복하기 위해, 완전 자동화된 이진 CNN 압축·배포 흐름을 설계한 점이 가장 큰 공헌이다. 먼저, 기존 TensorFlow 프로토콜 버퍼(.pb) 파일을 파싱해 그래프 최적화를 수행하고, 양자화된 가중치와 활성화를 1‑bit/2‑bit 형태로 변환한다. 이 과정에서 양자화 전후 서브그래프를 정리해 불필요한 연산을 제거하고, 32비트 워드 하나에 최대 32개의 1‑bit 가중치를 패킹함으로써 메모리 사용량을 크게 감소시킨다.
FPGA 가속기 설계에서는 두 단계의 병렬성을 도입한다. Processing Element(PE)는 32개의 이진 커널을 동시에 처리하고 32‑bit 누산기를 갖추어 intra‑kernel 병렬성을 구현한다. 여러 PE를 행렬 형태로 배열한 Processing Engine(PEN)은 서로 다른 커널을 동시에 적용해 inter‑kernel 병렬성을 확보한다. 설계 가정으로 출력 피처맵 수를 8의 배수, 입력 피처맵 수를 16의 배수로 제한해 대부분의 최신 네트워크 구조에 적용 가능하도록 하였으며, 온‑칩 메모리 제한을 고려해 메모리 사용량을 최소화한다.
데이터 순서 최적화는 또 다른 핵심 기법이다. 기존의 Depth×Width×Height 혹은 Depth×Height×Width 순서 대신 Height×Width×Depth(또는 Width×Height×Depth) 순서를 채택해 메모리 주소 연속성을 높이고, DRAM 버스트 전송 효율을 크게 향상시켰다. 이 방식은 로컬 RAM에서의 비트 패킹 작업을 단순화하고, 메모리 읽기·쓰기 회로 설계를 간소화한다.
실험에서는 YOLO‑v2 모델을 320×320 입력 크기로 재학습하고, 첫·마지막 레이어를 제외한 나머지를 1‑bit/2‑bit으로 양자화해 원본 255 MB 모델을 8.3 MB로 압축하였다. Cyclone‑V 5CSEA6 SoC에 구현된 이진 컨볼루션 가속기는 Altera HLS를 통해 자동 생성되었으며, 모바일 ARM Cortex‑A9 대비 평균 5.34배, 데스크톱 i7‑6800K 대비 1.78배 빠른 추론 속도를 보였다. 특히 이진 컨볼루션 연산만을 FPGA에서 가속했을 때는 모바일 CPU 대비 최대 11.5배의 속도 향상이 관찰되었다. 전체 파이프라인은 모델 파싱부터 FPGA 비트스트림 생성까지 약 1시간 내에 완료되어, 실무 적용 가능성을 크게 높였다. 다만 실시간 처리 수준에는 아직 미치지 못하며, 더 높은 병렬도와 메모리 대역폭 확보가 향후 과제로 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기