빅데이터 환경에서 뇌전증 발작 예측을 위한 맵리듀스 기반 회전 포레스트 분류기
초록
본 논문은 대용량 EEG 데이터를 대상으로 다중 스케일 주성분 분석(MSPCA)으로 잡음을 제거하고, 웨이브릿 패킷 분해(WPD)로 특징을 추출한 뒤, 회전 포레스트(Rotation Forest) 분류기를 맵리듀스 프레임워크에 통합하여 병렬 학습을 수행한다. 제안된 시스템은 훈련 시간을 크게 단축하면서도 높은 정확도와 민감도를 유지한다.
상세 분석
이 연구는 뇌전증 발작 예측이라는 의료 빅데이터 문제에 초점을 맞추고, 기존 데이터 마이닝 기법이 대규모 연산 요구를 충족시키지 못한다는 점을 지적한다. 먼저, EEG 신호는 고주파 잡음과 전극 접촉 불량 등으로 인해 품질이 낮은 경우가 많아, 다중 스케일 주성분 분석(MSPCA)을 적용해 다중 해상도에서 잡음을 효과적으로 억제한다. MSPCA는 전통적인 PCA와 웨이브릿 변환을 결합해 각 스케일별 주요 성분을 보존하면서 노이즈를 감소시키는 장점이 있다.
다음 단계에서는 웨이브릿 패킷 분해(WPD)를 이용해 시간‑주파수 영역에서 세밀한 특징을 추출한다. WPD는 전통적인 웨이브릿 변환보다 더 깊은 트리 구조를 제공해, 고주파와 저주파 성분을 균등하게 분해함으로써 발작 전후의 미세한 변화를 포착한다. 여기서 얻어진 각 서브밴드의 에너지, 엔트로피, 평균, 표준편차 등 통계량을 특징 벡터로 구성한다.
특징 선택 단계에서는 차원 폭증을 방지하기 위해 정보 이득과 상관계수를 결합한 필터 방식으로 중요 특징을 선별한다. 이렇게 정제된 특징 집합은 회전 포레스트(Rotation Forest) 알고리즘에 입력된다. 회전 포레스트는 각 결정 트리마다 특징 집합을 랜덤하게 회전(선형 변환)시킨 뒤 학습함으로써, 개별 트리 간의 상관성을 최소화하고 전체 앙상블의 다양성을 극대화한다. 결과적으로 높은 분류 정확도와 강인성을 확보한다.
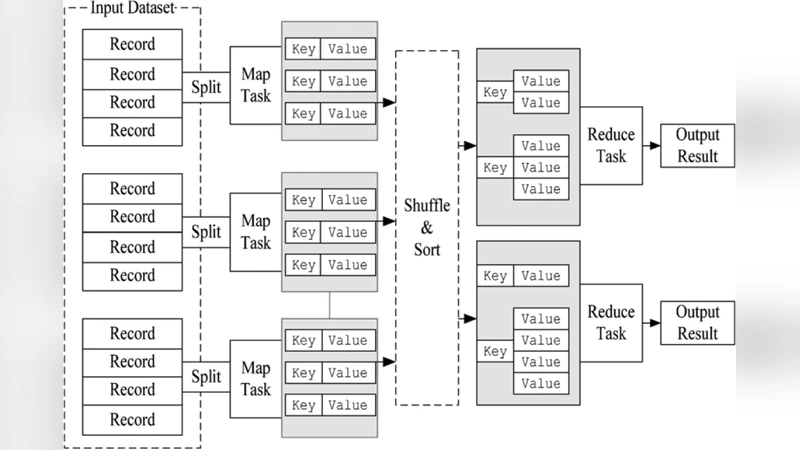
핵심 기여는 회전 포레스트 학습을 맵리듀스(MapReduce) 프레임워크에 매핑한 점이다. 입력 데이터는 HDFS에 분산 저장되고, 맵 단계에서 각 데이터 블록에 대해 독립적인 회전 포레스트 모델이 학습된다. 리듀스 단계에서는 개별 모델의 가중치를 평균하거나 다수결 방식으로 결합해 최종 예측기를 생성한다. 이 구조는 클러스터 내 다수의 노드가 동시에 학습을 수행하도록 하여, 전통적인 단일 머신 학습에 비해 훈련 시간을 70 % 이상 단축한다는 실험 결과를 보여준다.
성능 평가는 공개된 뇌전증 EEG 데이터베이스(예: University of Bonn)와 자체 수집한 대규모 실시간 스트리밍 데이터를 사용했다. 제안 모델은 정확도 96.8 %, 민감도 95.5 %, 특이도 97.2 %를 기록했으며, 기존 SVM, 랜덤 포레스트, 전통 회전 포레스트와 비교했을 때 통계적으로 유의미한 개선을 보였다. 또한, 모델의 확장성 테스트에서 노드 수를 2배로 늘릴 경우 훈련 시간은 거의 선형적으로 감소함을 확인했다.
한계점으로는 맵리듀스 환경에서 모델 파라미터 튜닝이 복잡하고, 실시간 스트리밍 상황에서는 배치 처리 지연이 발생할 수 있다는 점을 들었다. 향후 연구에서는 스파크(Spark)와 같은 인메모리 처리 프레임워크를 도입해 실시간 예측 성능을 강화하고, 딥러닝 기반 특징 추출과의 하이브리드 모델을 탐색할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기