시뮬레이터 환경 변수 활용한 로봇 제어 최적화: 교대 최적화와 베이지안 적분(ALOQ)
본 논문은 시뮬레이터에서 제어 정책과 환경 변수(관측되지 않는 물리적 요인)를 동시에 최적화하는 ALOQ(Alternating Optimisation and Quadrature) 알고리즘을 제안한다. 베이지안 최적화(BO)와 베이지안 적분(BQ)을 교대로 적용해 정책 π와 환경 변수 θ를 선택하고, 기대 보상을 효율적으로 추정한다. 특히 희귀 사건(rare events)이 정책 성능에 큰 영향을 미치는 상황에서도 샘플 효율성을 유지하며 강인한 …
저자: Supratik Paul, Konstantinos Chatzilygeroudis, Kamil Ciosek
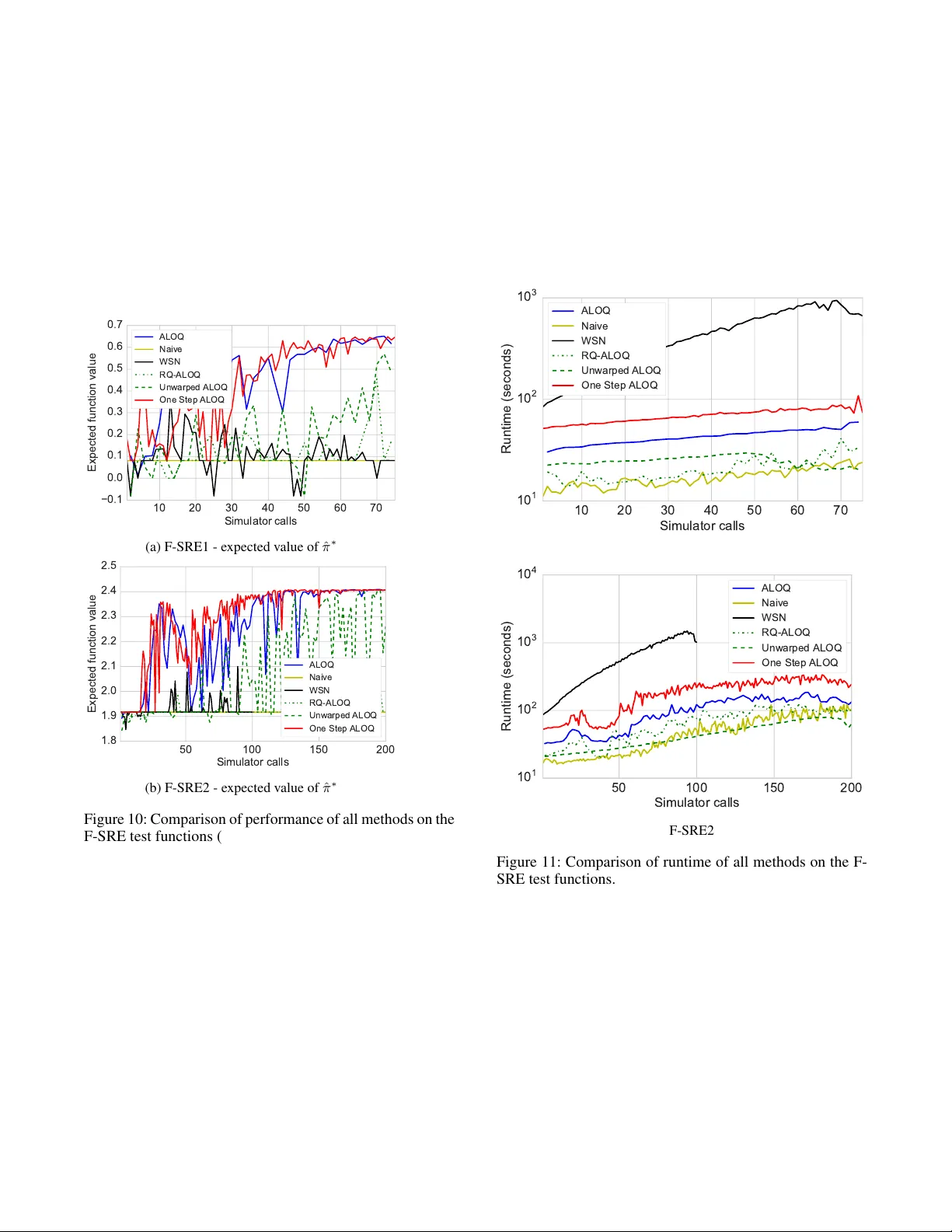
본 논문은 물리적 시스템을 시뮬레이터에서 학습할 때, 실제 환경에서 관측되지 않지만 시뮬레이터에서는 제어 가능한 ‘환경 변수’(environment variables) θ를 활용해 정책 π를 보다 강인하게 학습하는 방법을 제시한다. 기존 베이지안 최적화(BO) 기반 정책 탐색은 정책 파라미터만을 최적화하고, 환경 변수는 무작위로 샘플링한다. 이 접근법은 희귀 사건(rare events, SREs)이 기대 보상에 큰 영향을 미치는 경우, 해당 사건이 충분히 관측되지 않아 정책이 위험 상황에 취약해지는 문제점을 가진다. 예를 들어 로봇이 드물게 발생하는 센서 오차로 인해 장애물에 가까워지는 경우, 무작위 샘플링은 이러한 상황을 거의 만나지 못해 충돌 회피 정책을 학습하지 못한다.
이를 해결하기 위해 저자들은 Alternating Optimisation and Quadrature (ALOQ)라는 새로운 알고리즘을 설계했다. ALOQ는 두 가지 베이지안 기법을 교대로 적용한다. 첫 번째 단계에서는 현재까지 수집된 데이터 D를 기반으로 가우시안 프로세스(GP) 모델 f(π,θ)∼GP(m,k)를 학습한다. 이 GP는 정책과 환경 변수를 동시에 입력으로 받아 반환값(보상)을 예측한다. BO 단계에서는 GP를 이용해 정책에 대한 기대 보상 \(\bar f(\pi)=\mathbb{E}_\theta
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기