청각과 뇌파가 만든 음악 의미 임베딩
초록
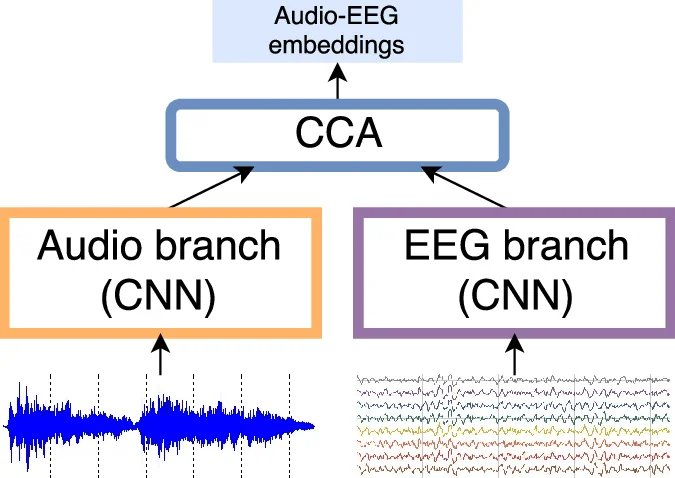
본 논문은 청취자의 뇌파(EEG) 데이터를 청각 신호와 함께 활용해 음악 의미 임베딩을 학습하는 새로운 프레임워크를 제시한다. 2‑뷰 신경망과 Deep Canonical Correlation Analysis(DCCA) 손실을 이용해 오디오와 EEG 임베딩을 최대한 상관시키며, 학습된 임베딩을 독립적인 음악‑가사 교차 검색 과제에 적용해 Spotify 기존 특징보다 우수한 성능을 보였다.
상세 분석
이 연구는 음악 의미 모델링에 ‘청취자 중심’ 접근을 도입한 점이 가장 혁신적이다. 기존 방법들은 주로 레이블(태그)이나 감정 차원과 같은 외부 주석에 의존했으며, 이는 주관적 의미를 충분히 포착하지 못한다는 한계가 있었다. 저자들은 EEG라는 직접적인 뇌 활동 측정을 정규화 신호로 활용함으로써, 인간이 음악을 인지할 때 발생하는 신경 패턴을 학습 목표에 포함시켰다. 이를 구현하기 위해 2‑view 구조의 딥 네트워크를 설계했으며, 각각 오디오와 EEG 입력을 1‑D 컨볼루션 레이어와 배치 정규화를 거쳐 고차원 임베딩으로 변환한다. 핵심은 DCCA 손실이다. DCCA는 두 뷰의 비선형 매핑 후 선형 CCA를 적용해 상관을 극대화하므로, 오디오와 EEG 사이의 복잡한 비선형 관계를 효과적으로 학습한다. 논문에서는 DCCA 최적화를 위해 공분산 행렬의 정규화와 고유값 분해를 명시적으로 구현하고, 최종 임베딩은 학습된 비선형 매핑 뒤에 선형 CCA를 적용해 얻는다.
데이터 측면에서 저자들은 18명의 피험자에게 60개의 음악 클립과 2개의 베이스라인(노이즈·침묵)을 청취하게 하고, 16채널 EEG를 250 Hz로 기록하였다. 전처리 단계에서는 전원 노이즈와 DC 오프셋 제거, 웨이브렛 기반 아티팩트 제거(WAR, WSD) 등을 적용해 신호 품질을 향상시켰다. 특히 채널·피험자 간 전극 접촉 차이를 보정하기 위해 각 채널·자극별로 -1~1 사이로 정규화한 점이 실험 재현성을 높였다.
학습된 임베딩의 일반화 성능을 검증하기 위해 독립적인 음악‑가사 교차 모달 검색 데이터셋을 사용했다. 여기서는 4‑layer 완전 연결 DCCA 모델을 가사와 오디오 각각에 적용해 64‑차원 공동 임베딩을 만든 뒤, 평균 역순위(MRR) 지표로 평가했다. 결과는 두 가지 기준(인스턴스 기반, 클래스 기반) 모두에서 Spotify의 65‑차원 특징보다 우수했으며, 700배 더 큰 데이터로 사전 학습된 최신 모델과도 비슷한 수준을 기록했다. 이는 적은 양의 EEG‑보강 데이터만으로도 강력한 의미 표현을 얻을 수 있음을 시사한다.
한계점으로는 EEG 데이터의 규모가 작고 피험자당 청취 시간도 제한적이라는 점, 그리고 EEG 신호 자체가 잡음에 민감해 전처리 비용이 크다는 점을 들 수 있다. 저자들은 더 많은 피험자와 다양한 장르·문화적 배경을 포함한 데이터 수집, 멀티‑모달 정규화 기법(예: 어텐션 기반 가중치) 도입, 그리고 실시간 추론을 위한 경량화 모델 설계 등을 향후 연구 방향으로 제시한다. 전체적으로 이 논문은 뇌-컴퓨터 인터페이스와 음악 정보 검색을 연결하는 새로운 패러다임을 제시하며, 멀티‑모달 딥러닝에서 인간 인지 신호를 정규화 신호로 활용하는 가능성을 크게 확장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기