과잉 사전 학습 기반 잡음 수준 추정: 엄격한 비대칭 경계와 고차원 분석
본 논문은 과잉(Overcomplete) 사전 학습 과정에서 발생하는 가우시안 잡음의 분산을, 학습된 사전의 고유값 스펙트럼을 이용해 정확히 추정하는 방법을 제시한다. 표본 공분산 행렬의 고유값 분포에 대한 엄밀한 확률론적 분석을 바탕으로, 잡음 고유값 영역의 비대칭 경계와 asymptotic behavior를 이용한 구간 제한 추정기를 설계하였다. 이론적 보증과 실험을 통해 기존 방법 대비 높은 정확도와 안정성을 확인하였다.
저자: ** Rui Chen, Changshui Yang* (Corresponding author), Huizhu Jia
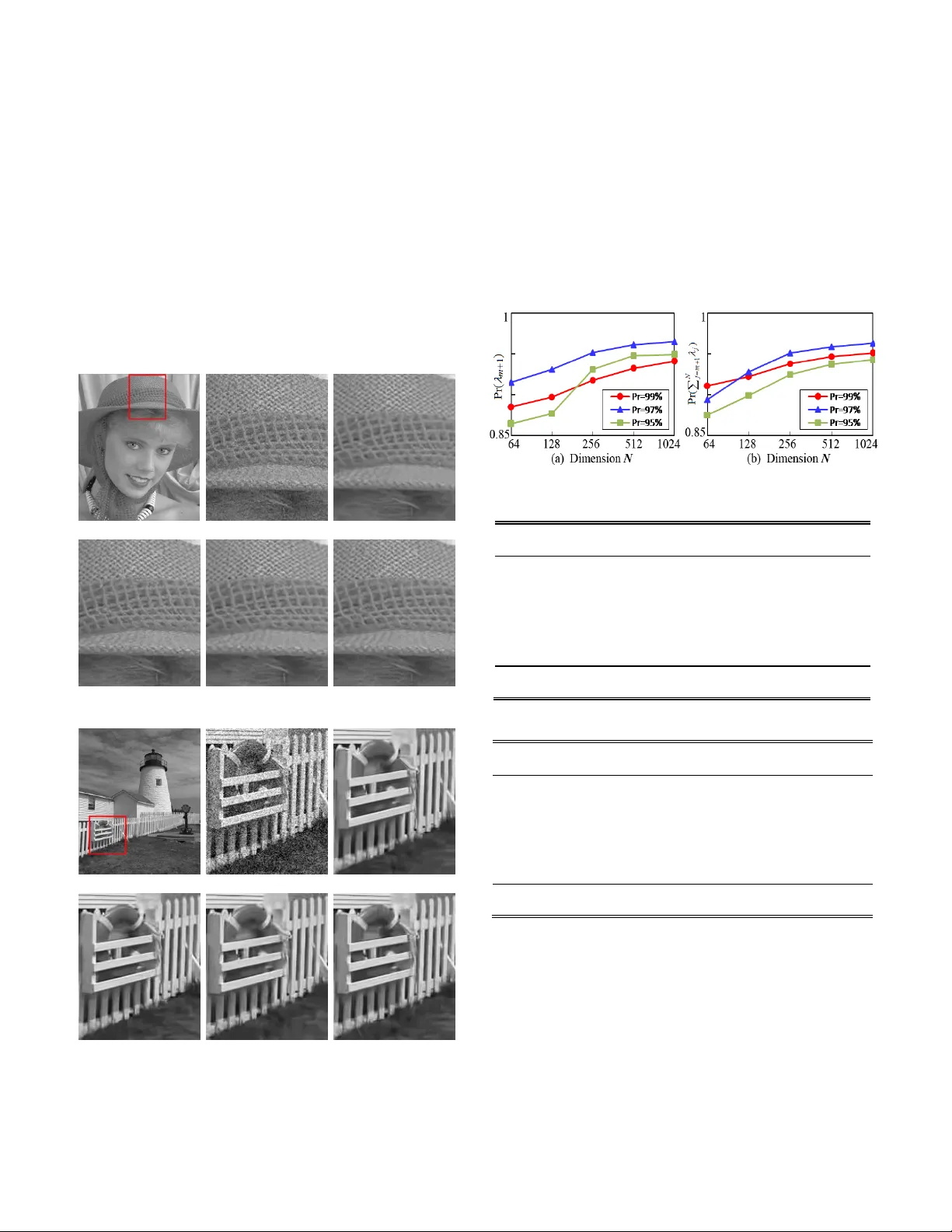
본 논문은 과잉 사전(Overcomplete Dictionary) 학습 과정에서 발생하는 가우시안 잡음의 분산을, 학습된 사전 자체만을 이용해 정확히 추정하는 새로운 방법론을 제시한다. 연구 동기는 사전 기반 신호 복원 및 압축 센싱 분야에서, 사전이 업데이트되는 단계마다 잡음 레벨을 정확히 파악해야 알고리즘의 수렴성과 복원 품질을 보장할 수 있다는 점에 있다. 기존의 잡음 추정 기법들은 주로 외부 검증 데이터나 잔차 분석에 의존했으며, 차원 수가 샘플 수보다 크게 클 경우 편향이 심하고, 사전이 과잉(overcomplete)일 때는 고유값 스펙트럼이 복잡해져 신뢰할 수 있는 추정이 어려웠다.
논문은 먼저 표본 공분산 행렬 \(\hat{\Sigma}= \frac{1}{n}XX^{\top}\) (여기서 \(X = D\alpha + N\), \(N\sim \mathcal{N}(0,\sigma^{2}I)\))의 고유값 분포에 대한 엄밀한 확률론적 분석을 수행한다. 고차원 asymptotic regime, 즉 \(m,n\to\infty\)이면서 \(\gamma = m/n\)가 일정한 경우에, Marčenko–Pastur 법칙을 확장하여 잡음 고유값 영역과 신호 고유값 영역 사이에 존재하는 스펙트럼 갭을 정량화한다. 이때 잡음 고유값은 거의 모두 \(\lambda\in
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기