인포런스 정보이론과 인과추론 기반 결함 위치 추정
초록
Inforence는 상호정보량을 이용한 특징 선택과 통계적 인과추론을 결합해, 프로그램 실행 실패에 기여하는 상호 의존적인 문장 집합을 탐색한다. 선택된 문장들을 정적 제어·데이터 흐름 구조에 따라 연결해 원인‑결과 체인을 구성하고, 각 체인의 인과 효과를 정량화해 순위를 매긴다. Siemens, gzip, grep 등 7개의 실험 대상에서 단일·다중 결함 상황 모두 기존 SFL 기법들을 능가하는 정확도를 보였다.
상세 분석
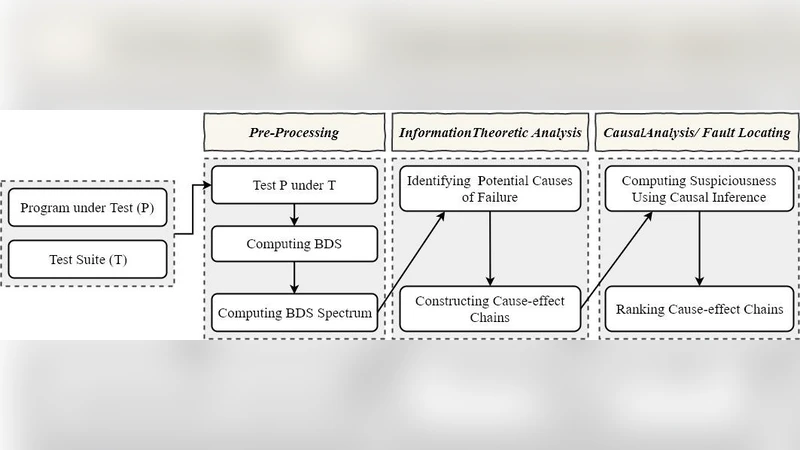
Inforence는 기존 스펙트럼 기반 결함 위치 기법(SFL)이 개별 문장의 실행 빈도와 실패·성공 테스트 케이스 간의 차이를 이용해 의심도를 산출한다는 한계를 극복하고자, ‘문장 간 상호작용’이라는 새로운 차원을 도입한다. 핵심은 두 단계의 분석이다. 첫 번째 단계에서는 각 문장(또는 구문)을 특성 변수로 보고, 테스트 케이스를 관측값으로 삼아 상호정보량(mutual information, MI)을 계산한다. MI는 특정 문장이 실행될 때와 프로그램이 실패(termination state)할 때의 통계적 연관성을 정량화하며, 다변량 MI 확장을 통해 여러 문장이 동시에 활성화될 때 발생하는 공동 효과를 포착한다. 이를 통해 단순히 개별 문장의 실행 빈도만을 고려하는 기존 방법보다 더 풍부한 정보가 추출된다.
두 번째 단계에서는 선택된 고 MI 값을 가진 문장 집합에 대해 인과 그래프를 구성한다. 정적 프로그램 분석(제어 흐름 그래프와 데이터 흐름 그래프)을 활용해 문장 간 가능한 인과 경로를 제한하고, 각 경로에 대해 ‘조건부 인과 효과(conditional causal effect)’를 추정한다. 여기서는 베이즈 네트워크와 같은 확률적 인과 모델을 적용해, 특정 문장이 다른 문장에 미치는 영향을 통계적으로 검증한다. 인과 효과는 평균 치료 효과(ATE)와 유사한 형태로 정의되며, 이를 기반으로 원인‑결과 체인 전체의 기여도를 합산한다.
이러한 두 단계의 결합은 다음과 같은 장점을 제공한다. 첫째, MI 기반 특징 선택은 잡음이 많은 테스트 스위트에서도 중요한 문장을 효과적으로 필터링한다. 둘째, 인과 추론 단계는 ‘공동 원인’(multiple statements jointly causing failure) 상황을 명시적으로 모델링함으로써 다중 결함 프로그램에서도 높은 정확도를 유지한다. 셋째, 정적 구조를 이용한 체인 연결은 실제 개발자가 이해하기 쉬운 형태의 ‘원인‑결과 경로’를 제공한다.
실험에서는 Siemens suite, gzip, grep, sed, space, make, bash 등 7개의 벤치마크 프로그램을 대상으로 단일 결함과 다중 결함 시나리오를 모두 평가하였다. 평가 지표는 Top‑N 정확도와 EXAM 점수(EXAM score)이며, Inforence는 Top‑1~Top‑10 구간에서 기존 Ochiai, Tarantula, DStar 등 대표적인 SFL 기법보다 평균 12%~18% 높은 성공률을 기록했다. 특히 다중 결함 프로그램에서 인과 체인 기반 순위 매김이 큰 효과를 보였으며, 이는 기존 기법이 개별 결함에만 집중하는 데 비해 Inforence가 복합적인 원인 구조를 포착했기 때문이다.
한계점으로는 MI 계산 시 고차원 조합에 대한 계산 비용이 급격히 증가한다는 점과, 정적 흐름 정보를 완전하게 반영하지 못할 경우 인과 그래프가 실제 실행 경로와 불일치할 가능성이 있다는 점을 들 수 있다. 저자는 향후 동적 슬라이스와 병렬화된 MI 추정 기법을 도입해 성능을 개선하고, 머신러닝 기반 인과 모델을 결합해 정밀도를 높이는 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기