숨소리만으로 화자 식별하기
본 논문은 연속 발화 중 발생하는 흡기음, 즉 숨소리의 스펙트럼 특성을 이용해 화자를 구별할 수 있음을 실증한다. i‑vector와 constant‑Q 스펙트로그램 기반 CNN‑LSTM 모델을 적용했으며, 깨끗한 고품질 데이터에서 70% 이상 정확도를 달성하였다.
저자: Wenbo Zhao, Yang Gao, Rita Singh
1. 서론
연속 발화 중 화자는 일정 주기로 흡기를 수행한다. 기존 연구는 흡기의 패턴·리듬·에너지 수준을 분석했지만, 흡기 자체가 내는 소리, 즉 ‘숨소리’를 화자 식별에 활용한 사례는 거의 없었다. 흡기 시 구강과 성문이 완전히 열려 성도가 자연 상태에 가깝게 노출되므로, 공명 주파수와 난류음의 스펙트럼이 화자마다 고유하게 나타난다. 이러한 비자발적 특성을 이용하면, 발화 중 의도적 변조나 위장에 강인한 화자 인증이 가능하다.
2. 선행 연구
음성 기반 화자 인식은 수십 년간 MFCC, i‑vector, x‑vector 등으로 발전해 왔으며, 법의학·보안 분야에 널리 적용된다. 그러나 숨소리를 이용한 연구는 주로 의료 분야에서 환자의 호흡 상태를 진단하는 수준에 머물렀다. 본 논문은 이러한 격차를 메우고, 숨소리를 화자 바이오‑시그니처로 전환한다.
3. 특징 추출 방법
3.1 i‑vector 기반 특징
- MFCC를 추출하고 512‑component GMM‑UBM을 학습한다.
- 각 화자에 대해 GMM‑Supervector를 만든 뒤, 총변동 공간(T) 행렬을 이용해 저차원 i‑vector를 추출한다.
- i‑vector는 길이 정규화와 중심화 과정을 거쳐 분류기에 입력된다.
3.2 Constant‑Q 스펙트로그램 기반 특징
- 각 프레임(20~30 ms)마다 constant‑Q 변환을 적용해 로그‑스케일 주파수 해상도의 스펙트럼을 얻는다.
- 48 filters per octave, 8 octave 범위(27.5 Hz~22 kHz)로 구성해 463 × T 형태의 2‑D 이미지로 변환한다.
- 이 스펙트로그램은 CNN‑LSTM 네트워크의 입력으로 사용된다.
4. CNN‑LSTM 모델 설계
- 입력: 463 × T constant‑Q 스펙트로그램.
- Conv 레이어: 8 × 3 × 3 필터, ReLU 활성화, 2 × 1 맥스풀링.
- LSTM 레이어: 시계열 특성을 학습, 마지막 타임스텝 출력 사용.
- Dropout(0.4) → Fully‑Connected → Softmax(44 classes).
- 손실: 다중 클래스 KL‑다이버전스, 최적화는 Adadelta(ρ=0.9).
5. 데이터 및 실험 설계
- LDC Hub‑4 1997 Broadcast News 데이터베이스에서 자동 음소 인식(Sphinx‑3)으로 ‘breath’ 음소를 추출.
- 고품질 읽기 발화만 선택, 16 kHz 샘플링.
- i‑vector 실험: 50명, 9,915 샘플, 70/30 학습/테스트 비율.
- CNN‑LSTM 실험: 44명, 9,376 샘플, 70/20/10 학습/검증/테스트 비율.
- 데이터 증강: elastic transform(σ=2, α=15) 적용.
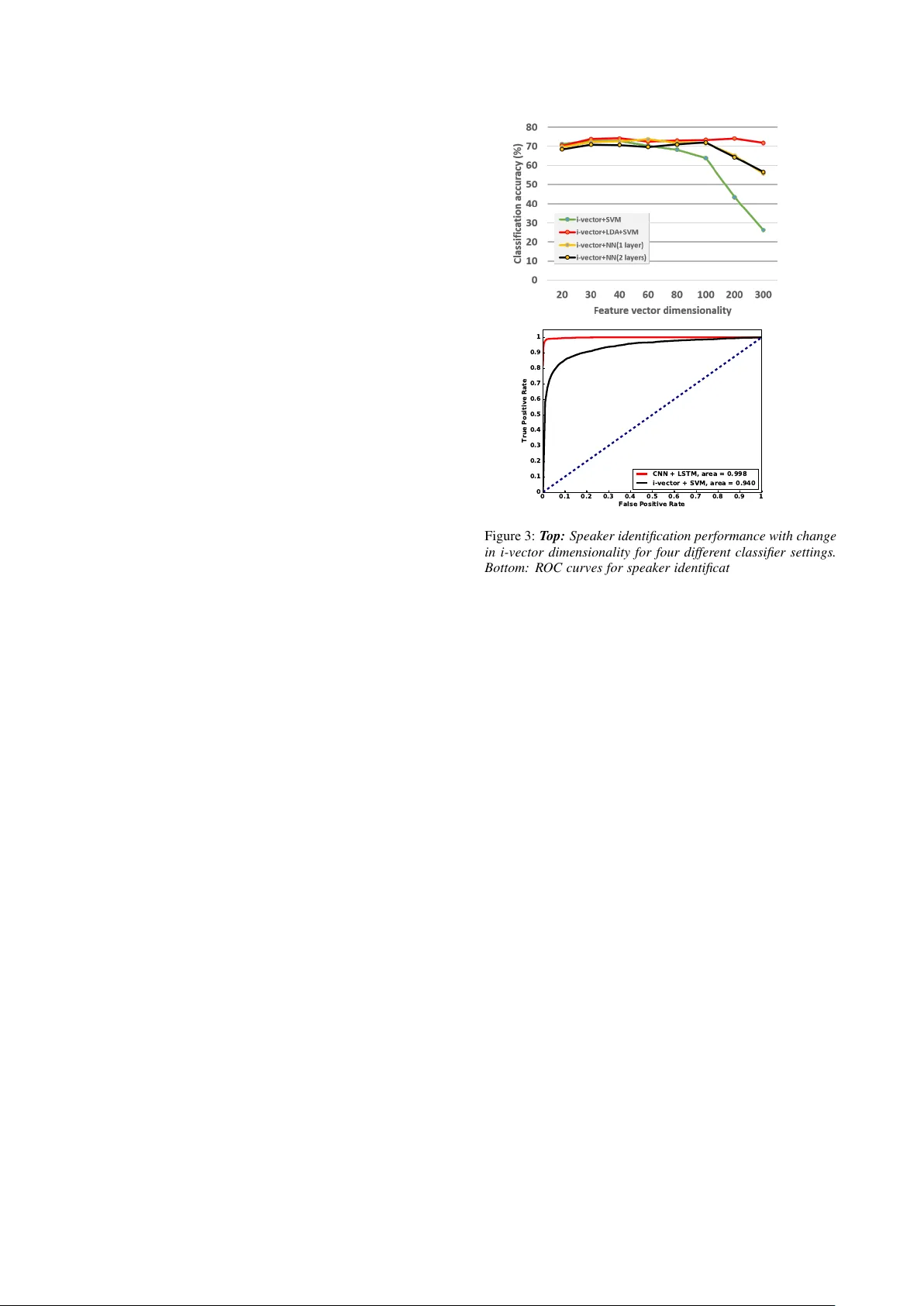
6. 결과
- i‑vector + SVM: 72.8%
- i‑vector + 1‑layer NN: 73.5%
- i‑vector + 2‑layer NN: 71.9%
- i‑vector + LDA + SVM: 74.1% (최고)
- CNN‑LSTM: 약 78% 이상 정확도, 특히 짧은 흡기 구간에서도 안정적인 분류 성능을 보임.
7. 논의 및 한계
- 숨소리는 화자 고유의 해부학적·생리학적 정보를 담고 있어, 변조나 위장에 강인한 특성을 제공한다.
- 현재 실험은 깨끗한 고품질 환경에 한정되었으며, 잡음, 채널 변동, 다양한 언어·방식에 대한 일반화는 미검증이다.
- 실시간 적용을 위한 모델 경량화와, 숨소리 데이터의 프라이버시·보안 이슈에 대한 윤리적 검토가 필요하다.
8. 결론 및 향후 연구
숨소리만으로도 화자 식별이 가능함을 입증했으며, i‑vector와 CNN‑LSTM 두 가지 접근법 모두 실용적인 성능을 보였다. 향후에는 다채널·노이즈 환경, 실시간 스트리밍, 그리고 멀티‑모달(음성+숨소리) 결합 모델을 개발해 법의학·보안 분야에 적용하는 연구가 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기