가상 시연에서 실제 로봇 조작으로의 전이 LSTM과 MDN 기반 학습
초록
가상 환경에서 수집한 시연 데이터를 LSTM‑MDN 네트워크로 학습시켜, 물리적 Baxter 로봇이 ADL(일상생활동작) 과제를 성공적으로 수행하도록 한 연구이다. LSTM의 순차 기억과 MDN의 다중모달 출력이 기존 피드포워드‑MSE 방식보다 우수함을 실험으로 입증하고, 불완전한 시연을 포함한 학습이 로봇의 오류 교정 능력을 향상시킴을 보여준다.
상세 분석
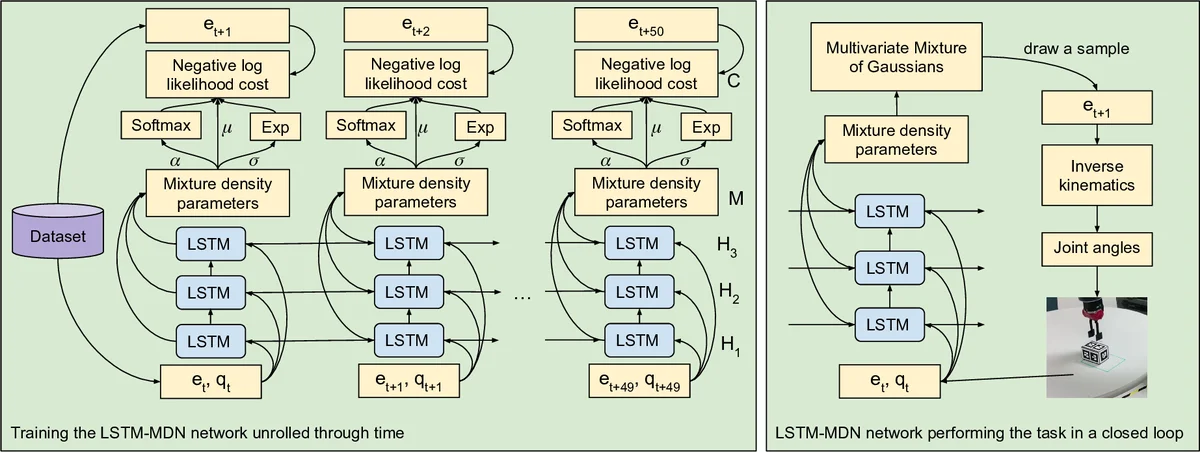
본 논문은 보조 로봇이 장애인·노인 가정에서 일상생활동작(ADL)을 수행하도록 하기 위한 ‘가상 시연 → 실제 로봇’ 전이 파이프라인을 제안한다. 핵심은 두 가지 딥러닝 기법의 결합이다. 첫째, LSTM(Long Short‑Term Memory) 구조를 사용해 시연 궤적을 시간 순서대로 모델링한다. LSTM은 과거 상태를 기억함으로써 다단계 작업(예: 물건을 잡고, 이동하고, 놓는 일련의 순서)에서 단계 간 의존성을 학습한다. 논문에서는 3개의 LSTM 레이어(각 50노드)를 쌓아 깊은 시퀀스 모델을 구성했으며, 이는 단순 피드포워드 네트워크가 갖는 “순서 무시” 한계를 극복한다. 둘째, 출력층에 Mixture Density Network(MDN)를 도입해 다중 모달 확률 분포를 예측한다. ADL 과제는 동일 목표에 대해 여러 실행 경로가 존재할 수 있는데, 평균 제곱오차(MSE) 기반 학습은 이러한 경로들을 평균화해 비현실적인 중간 행동을 생성한다. MDN은 가우시안 혼합 모델을 통해 각 시점에서 가능한 여러 행동을 확률적으로 표현하고, 네거티브 로그우도 손실을 최소화함으로써 실제 시연의 다양성을 보존한다.
데이터 측면에서 저자는 Unity3D 기반 가상 환경을 구축해 사용자가 마우스·키보드로 7자유도 그리퍼를 조작하도록 했다. 두 가지 과제—‘픽‑앤‑플레이스’와 ‘목표 자세로 밀기’—를 각각 650·1614개의 원시 시연으로 수집하고, 33 Hz에서 4 Hz로 다운샘플링·좌우 이동 변형을 통해 총 31 200·12 912개의 학습 궤적을 생성했다. 이는 시연 수가 제한된 상황에서도 데이터 다양성을 확보하는 실용적 전략이다.
전이 단계에서는 가상 시연에서 학습된 LSTM‑MDN 모델을 Baxter 로봇에 적용한다. 로봇은 오프‑더‑쉘프 비전 모듈로 물체 위치를 추정하고, 역기구학을 통해 LSTM이 예측한 목표 그리퍼 포즈를 실제 관절 명령으로 변환한다. 실험 결과, LSTM‑MDN 컨트롤러는 90 % 이상의 성공률로 두 과제를 수행했으며, 동일 환경에서 피드포워드‑MSE 모델은 현저히 낮은 성공률을 보였다. 또한, 불완전하거나 실패한 시연을 포함한 학습 데이터가 로봇에게 “실패 복구” 행동을 학습하게 하여, 실제 실행 중 발생하는 작은 오차를 자체적으로 교정하는 능력을 부여했다.
이 연구는 (1) 가상 시연 기반 학습이 물리적 로봇에 직접 적용 가능함, (2) 순차 기억과 다중모달 출력이 결합된 LSTM‑MDN 구조가 기존 방법보다 우수함, (3) 불완전 시연을 활용한 학습이 로봇의 오류 복구 능력을 향상시킨다는 세 가지 주요 기여를 입증한다. 향후 연구에서는 도메인 랜덤화와 실제 사용자 피드백을 결합해 일반화 성능을 더욱 강화하고, 더 복잡한 다관절 로봇 및 다양한 ADL 시나리오에 적용하는 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기