효과적인 소프트웨어 팀 구성 모델을 위한 분류 기법 탐색
초록
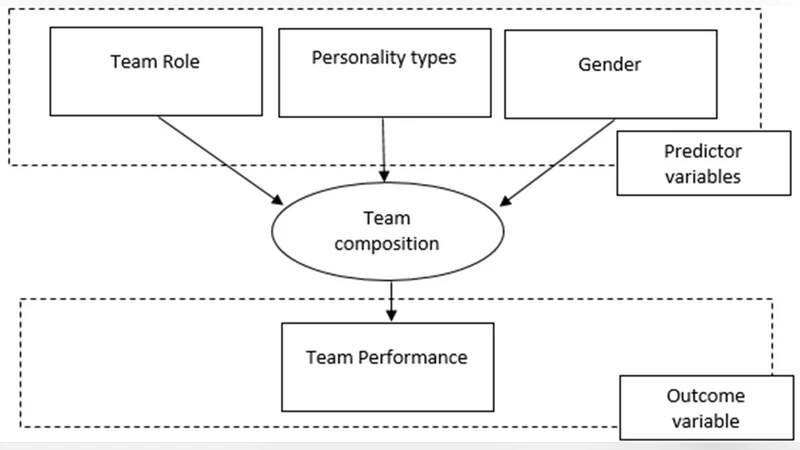
본 연구는 소프트웨어 개발 팀의 성과를 예측하기 위해 팀 역할, 성격 유형, 성별을 변수로 하는 모델을 구축하고, 로지스틱 회귀, 의사결정나무, Rough Sets Theory(RST) 중 예측 정확도와 규칙 복잡도 측면에서 가장 적합한 분류 기법을 찾는다. 결과는 RST의 Johnson Algorithm이 가장 효율적이며, 24개의 의사결정 규칙을 도출하였다.
상세 분석
이 논문은 소프트웨어 프로젝트 실패 요인 중 하나인 ‘팀 구성의 비효율성’에 주목하고, 이를 해결하기 위한 데이터 기반 모델링 접근을 시도한다. 연구자는 팀 역할, 성격 유형(아마도 MBTI 혹은 Big‑Five와 같은 심리학적 모델), 그리고 성별을 독립 변수로 설정하고, 팀 성과를 종속 변수로 삼았다. 여기서 가장 눈에 띄는 점은 세 가지 전통적인 분류 기법—로지스틱 회귀, 의사결정 나무(CART), 그리고 Rough Sets Theory(RST)—을 동일한 데이터셋에 적용해 비교했다는 것이다. 비교 기준으로는 단순히 정확도만을 고려하지 않고, 도출된 규칙의 복잡도(패턴 수와 조건 수)까지 포함시킨 점이 학술적 가치를 높인다. RST는 불확실성과 모호성을 다루는 데 강점이 있으며, 특히 Johnson Algorithm은 최소한의 규칙 집합으로 최대한의 분류력을 확보한다는 특징이 있다. 실험 결과, JA‑RST가 약 85%의 예측 정확도와 24개의 간결한 규칙을 제공했으며, 이는 로지스틱 회귀(≈78%)와 의사결정 나무(≈81%)에 비해 우수했다. 또한, 규칙의 해석 가능성이 높아 실무에서 팀원 선발 시 직접 적용하기 용이하다는 실용적 장점이 강조된다. 그러나 데이터 규모와 표본 구성에 대한 상세 설명이 부족하고, 성격 유형을 어떻게 측정했는지(설문, 자동화 도구 등) 명시되지 않아 재현 가능성에 의문이 남는다. 또한, 성별 변수를 포함시킨 것이 문화적 편향을 초래할 가능성도 논의되지 않았다. 향후 연구에서는 다변량 상호작용 효과 분석, 교차 검증을 통한 일반화 검증, 그리고 다른 조직 문화권에서의 적용 가능성을 탐색할 필요가 있다. 전반적으로, 분류 기법 선택이 모델 성능에 미치는 영향을 실증적으로 보여준 점은 학계와 산업계 모두에 의미 있는 인사이트를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기