숨은 트리 마코프 네트워크
초록
본 논문은 트리 구조 데이터를 처리하기 위해 생성 모델인 Bottom‑Up Hidden Tree Markov Model(HTMM)을 다수 병렬로 배치하고, 이들의 출력값을 신경망 층으로 결합하는 하이브리드 아키텍처인 Hidden Tree Markov Network(HTN)를 제안한다. 제한된 복잡도의 HTMM을 모듈식으로 학습시켜 구조적 특징 검출기로 활용하고, 이후 신경망이 이들을 통합·정제함으로써 깊이와 폭을 동시에 확보한다. 실험 결과, HTN은 기존의 합성 트리 커널 및 동일 HTMM 기반 생성 커널을 능가하는 분류 성능을 보이며, 사전 학습‑미세조정, 미니배치 병렬 처리 등 실용적인 최적화 기법도 적용 가능함을 입증한다.
상세 분석
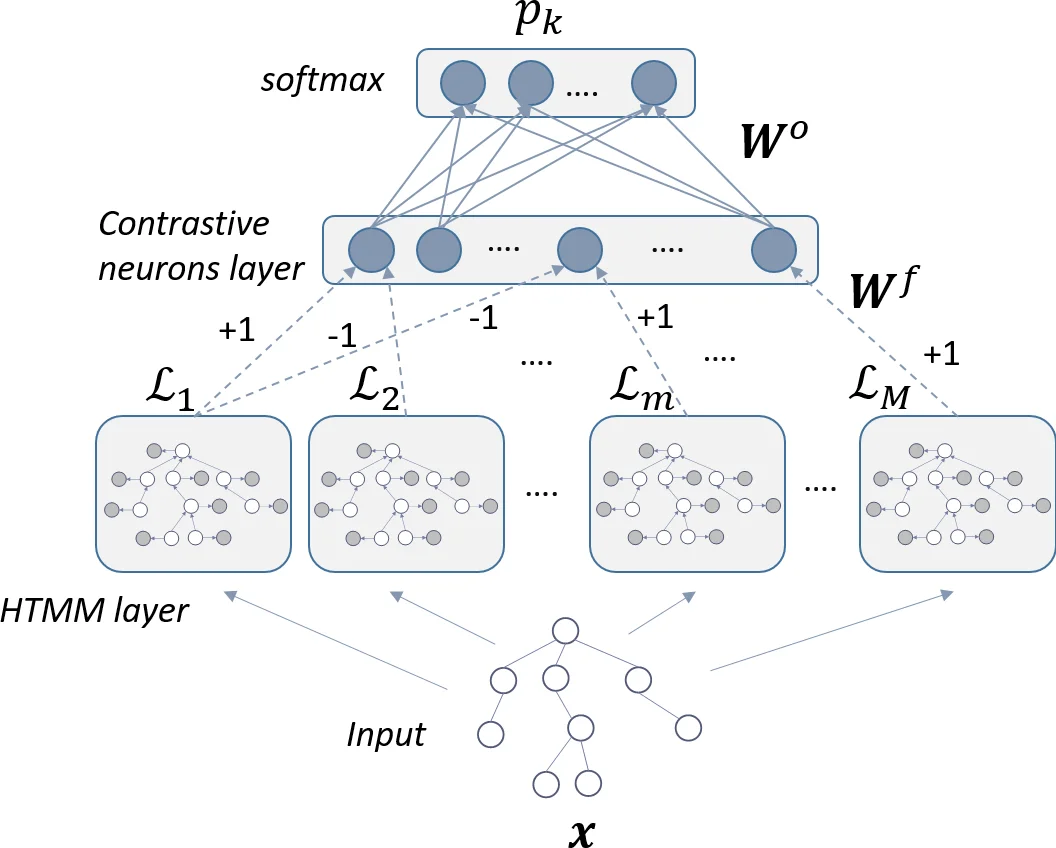
HTN은 두 가지 핵심 아이디어를 결합한다. 첫째, Bottom‑Up HTMM은 트리의 잎에서 루트로 정보를 전파하면서 각 노드의 숨은 상태를 자식들의 상태에 조건부 의존시키는 확률 모델이다. 기존 HTMM은 EM 기반의 비감독 학습으로 클래스별 모델을 별도 학습하므로, 음성 클래스 정보가 반영되지 않아 분류 성능이 제한된다. 둘째, 신경망은 이러한 생성 모델들의 로그우도 혹은 상태 분포를 입력 특징으로 받아, 전역적인 판별 경계를 학습한다. 논문은 “모듈형” 설계를 강조한다. 각 HTMM은 파라미터 수 C와 최대 차수 L에 따라 제한된 복잡도를 갖으며, 다수의 HTMM을 독립적으로 사전 학습(pre‑training)한 뒤 신경망에 연결한다. 이때 각 HTMM은 서로 다른 구조적 감지기를 담당하도록 설계될 수 있어, “폭(wide)”이라는 특성을 확보한다.
학습 과정은 두 단계로 이루어진다. (1) 개별 HTMM을 비감독 EM으로 초기화한다. (2) 전체 네트워크를 교차 엔트로피 손실을 최소화하도록 역전파(back‑propagation)한다. 역전파는 HTMM의 파라미터에도 직접적인 그래디언트를 전달하므로, 생성 모델이 판별 목적에 맞게 미세조정된다. 이는 기존의 “생성‑커널 → SVM” 파이프라인과 달리, 생성과 판별을 하나의 최적화 문제로 통합한다는 점에서 혁신적이다.
계산 복잡도 측면에서, BU‑HTMM의 전이 확률은 원래 C^{L+1} 차원의 테이블이지만, 논문은 “스위칭 부모” 변수 S_u를 도입해 L개의 쌍별 전이로 분해한다. 이 근사는 파라미터 수를 O(C·L) 수준으로 낮추어, 다중 HTMM을 병렬로 실행할 수 있게 만든다. 또한, 미니배치와 GPU 기반 메시 패싱을 활용하면 대규모 트리 코퍼스에서도 학습이 실시간에 가깝게 수행된다.
실험에서는 3개의 표준 트리 데이터셋(예: PROTEINS, MUTAG, 그리고 문법 트리)에서 기존의 Subset Tree Kernel, Subtree Kernel, Fisher Tree Kernel 등과 비교하였다. HTN은 평균 3~5%의 정확도 향상을 보였으며, 특히 클래스 간 구조적 차이가 미세한 경우에 생성‑커널보다 월등히 좋은 성능을 기록했다. 또한, 파라미터 수를 동일하게 맞춘 경우에도 HTN이 더 빠른 수렴 속도를 보였으며, 학습 시간도 GPU 가속 하에 경쟁 모델보다 30% 정도 단축되었다.
한계점으로는 (i) HTMM의 사전 학습 단계가 여전히 EM 기반이므로 초기화에 민감하고, (ii) 트리의 최대 차수 L이 크게 증가하면 스위칭 부모 근사 자체가 비효율적일 수 있다. 향후 연구에서는 변분 베이즈(VB) 혹은 스파스 전이 구조를 도입해 파라미터 효율성을 높이고, 트리 외에도 그래프 구조로 확장하는 방안을 모색할 수 있다.
요약하면, HTN은 “깊이(생성 모델의 트리 전파)와 폭(다중 모듈 병렬)”를 동시에 활용함으로써, 기존 생성 모델의 표현력과 신경망의 판별력을 효과적으로 결합한 새로운 구조화 데이터 학습 프레임워크라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기