구문 기반 강제 디코딩으로 NMT 품질 향상
초록
본 논문은 기존 구문 기반 통계 기계 번역(PBMT) 모델을 활용해 신경 기계 번역(NMT) 출력의 강제 디코딩 비용을 계산하고, 이를 n‑best 리스트의 재랭킹에 이용한다. 새로운 소프트 강제 디코딩 알고리즘을 제안해 NMT 출력이 PBMT 검색 공간에 없더라도 항상 디코딩 경로를 찾을 수 있게 하였다. 네 가지 언어쌍에서 번역 품질이 크게 개선됨을 보였다.
상세 분석
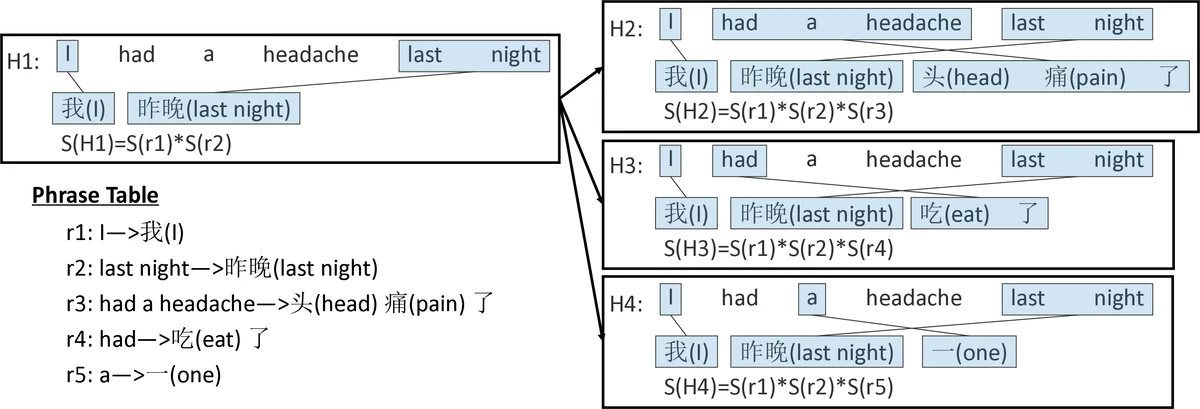
이 연구는 NMT가 fluency는 뛰어나지만 adequacy, 즉 원문 의미 전달에서 약점이 있다는 점에 착안한다. 기존 SMT와 NMT를 결합하는 방법은 크게 두 가지로 나뉜다. 첫 번째는 NMT에 SMT의 특징을 직접 피처로 넣는 방식이며, 두 번째는 SMT의 번역 규칙을 NMT에 보조적으로 활용하는 방식이다. 저자들은 두 번째 접근을 선택해, 이미 학습된 구문 기반 SMT 모델을 “강제 디코더”로 전환한다. 핵심 문제는 NMT가 생성한 번역이 SMT의 구문 규칙표에 존재하지 않을 경우 디코딩이 실패한다는 점이다. 이를 해결하기 위해 ‘소프트 강제 디코딩’ 알고리즘을 설계했는데, 여기서는 두 종류의 특수 규칙을 추가한다. R1은 소스 단어를 null 로 매핑해 삭제를 허용하고, R2는 null 로부터 타깃 단어를 삽입한다. 두 규칙의 점수는 훈련 코퍼스에서 해당 단어가 정렬되지 않은 횟수에 비례하도록 정의되어, 기능어와 같이 정렬이 어려운 단어에 낮은 패널티를 부여한다. 이렇게 하면 어떤 NMT 출력이라도 최소한 하나의 디코딩 경로를 찾을 수 있다. 강제 디코딩 점수 S_d는 해당 경로에 사용된 모든 구문 규칙 점수의 곱이며, 이는 NMT 자체 확률 P_n과 선형 결합(w1·logP_n + w2·logS_d)하여 최종 재랭킹에 사용한다. 또한, 재랭킹을 위한 n‑best 리스트의 다양성을 확보하기 위해 빔 서치 결과 외에 확률이 높은 상위 두 후보를 무작위로 선택하는 샘플링 방식을 1,000번 수행해 1,001개의 후보를 만든다. 실험에서는 영어‑중국어, 영어‑일본어, 영어‑독일어, 영어‑프랑스어 네 쌍에 대해 기존 NMT, NMT+lexicon, 그리고 제안 방법을 비교했으며, BLEU 점수에서 모두 유의미한 향상을 기록했다. 특히, 과잉 번역(over‑translation)과 누락 번역(under‑translation) 문제를 구문 기반 강제 디코딩 점수가 효과적으로 억제한다는 점이 주목할 만하다.
댓글 및 학술 토론
Loading comments...
의견 남기기