다중해상도 완전합성 신경망을 이용한 단일채널 오디오 분리
본 논문은 각 층에 서로 다른 크기의 필터를 배치해 다중해상도 특징을 추출하는 MR‑FCNN을 제안한다. 이를 음성·악기 혼합 신호의 단일채널(source‑separation) 문제에 적용해 기존 DNN 및 단일해상도 FCNN보다 SDR·SIR·SAR 측면에서 향상된 성능을 보였다.
저자: Emad M. Grais, Hagen Wierstorf, Dominic Ward
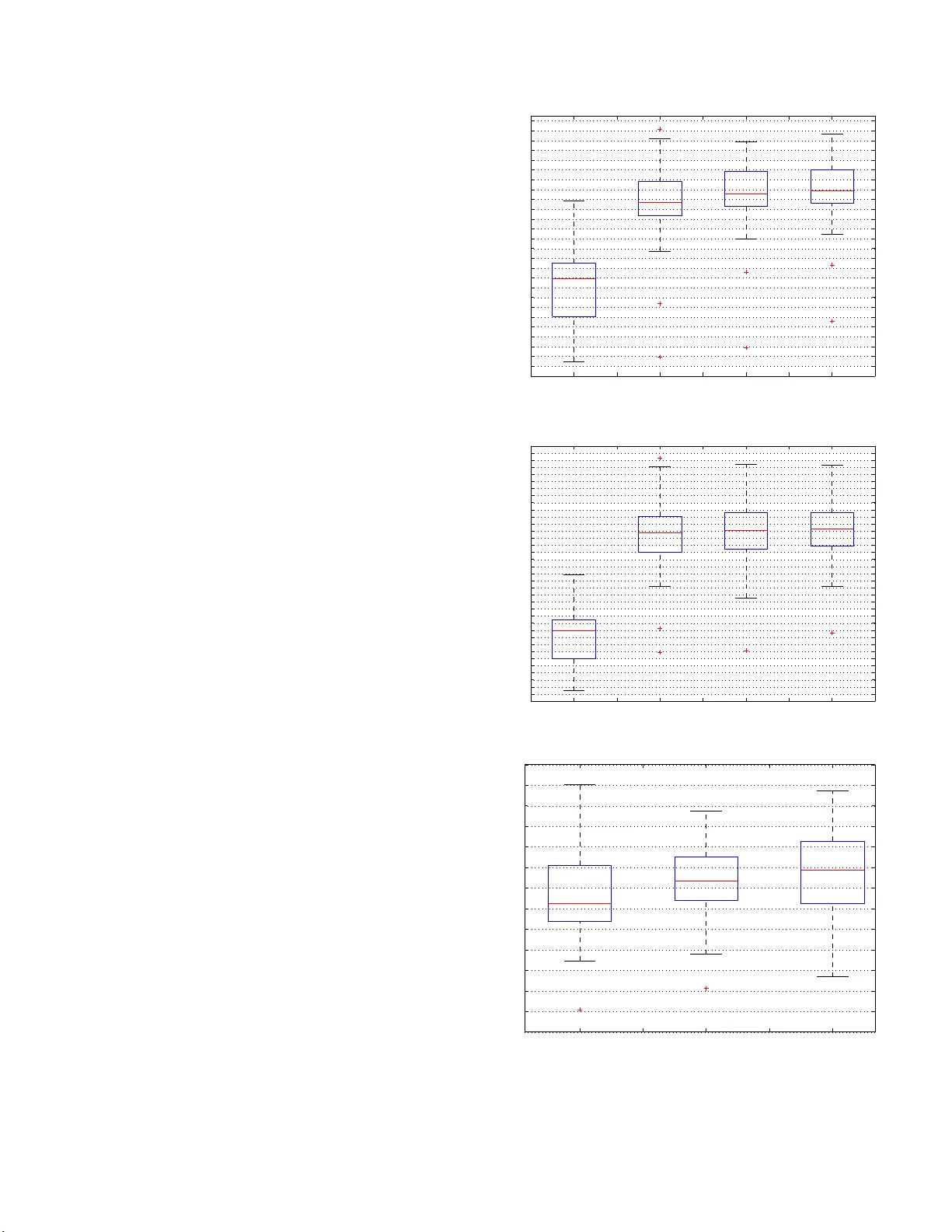
본 논문은 단일채널 오디오 소스 분리(MASS) 문제에 대한 새로운 딥러닝 접근법을 제시한다. 기존의 컨볼루션 신경망은 각 층마다 동일한 크기의 필터를 사용해 고정된 receptive field(RF)를 갖는다. 큰 RF는 전역적인 구조를, 작은 RF는 세밀한 디테일을 포착하지만, 하나의 해상도만을 사용하면 복합적인 스펙트로‑템포럴 패턴을 충분히 모델링하기 어렵다. 이를 해결하고자 저자들은 “Multi‑Resolution Fully Convolutional Neural Network”(MR‑FCNN)를 고안했으며, 각 층에 서로 다른 크기의 필터 집합을 동시에 배치한다. 구체적으로, 각 층은 13×21, 7×9, 3×3 크기의 2‑D 필터를 각각 12·3·3개 정도 사용해 총 18개의 특징 맵을 생성한다. 큰 필터는 전체 스펙트로그램의 전역 형태를, 중간 필터는 중간 스케일의 패턴을, 작은 필터는 고주파수·짧은 시간 변화를 포착한다. 이렇게 얻어진 다중해상도 특징은 ReLU 활성화 후 다음 층으로 전달되며, 인코더‑디코더 구조를 유지하면서도 풀링·업샘플링 없이 전부 2‑D 컨볼루션만으로 구현된다.
입력은 혼합 신호의 magnitude spectrogram을 15프레임(시간) × 1025주파수 bin(주파수) 크기의 2‑D 세그먼트로 나눈 것이며, 출력은 동일한 형태의 타깃 소스 spectrogram이다. 손실 함수는 출력과 정답 spectrogram 사이의 L2 차이이며, Adam 옵티마이저(β1=0.9, β2=0.999, ε=1e‑8)와 학습률 스케줄링을 통해 최적화한다. 파라미터 수는 558,181개로, 비교 모델인 DNN(4,206,600개)와 FCNN(445,173개)보다 적당히 큰 편이다.
실험은 SiSEC‑2015‑MUS 데이터셋의 100곡을 사용했다. 스테레오 곡을 평균해 모노로 변환하고, 44.1 kHz 샘플링, 2048‑point FFT, 512‑point hop size, 20 ms 한닝 윈도우를 적용해 magnitude spectrogram을 얻었다. 앞 50곡을 학습·검증, 뒤 50곡을 테스트에 사용하였다. 평가 지표는 BSS_EVAL 패키지의 SDR(전반적인 왜곡), SIR(간섭 억제), SAR(인공물)이다. 결과는 MR‑FCNN이 DNN 및 단일해상도 FCNN에 비해 모든 지표에서 우수함을 보여준다. 특히 SIR과 SAR에서 큰 폭의 개선이 관찰되었으며, 이는 다중해상도 필터가 소스별 고유 패턴을 더 정확히 구분하고, 불필요한 잡음·인공물을 최소화한다는 것을 의미한다.
논문은 또한 모델 설계상의 선택 사항을 논의한다. 필터 집합의 수와 크기를 3가지로 제한했으며, 이는 실험적 튜닝을 통해 얻은 경험적 값이다. 파라미터 수를 맞추기 위해 FCNN과 MR‑FCNN의 필터 수·크기를 조정했으며, 이는 공정한 비교를 위한 조치이다. 한계점으로는 필터 조합이 데이터에 따라 민감하게 작용할 수 있다는 점, 연산량이 증가할 가능성, 그리고 현재는 보컬 분리만을 대상으로 했다는 점을 들었다. 향후 연구에서는 자동화된 하이퍼파라미터 탐색, 다른 악기·음성 분리 작업, 실시간 처리 가능성, 그리고 비지도 학습과의 결합 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기