심층 신경망을 위한 임베딩 기반 화자 적응 학습
초록
본 논문은 화자 임베딩(i‑vector)을 제어 네트워크에 입력으로 사용해, 각 은닉층의 출력에 층별 요소별 선형 변환을 적용함으로써 내부 특징 공간을 화자에 독립적으로 정규화하는 화자 적응 학습(SAT) 방식을 제안한다. 제안 기법은 기존 i‑vector 기반 입력 특성 결합보다 LVCSR 과제에서 일관된 WER 감소 효과를 보였다.
상세 분석
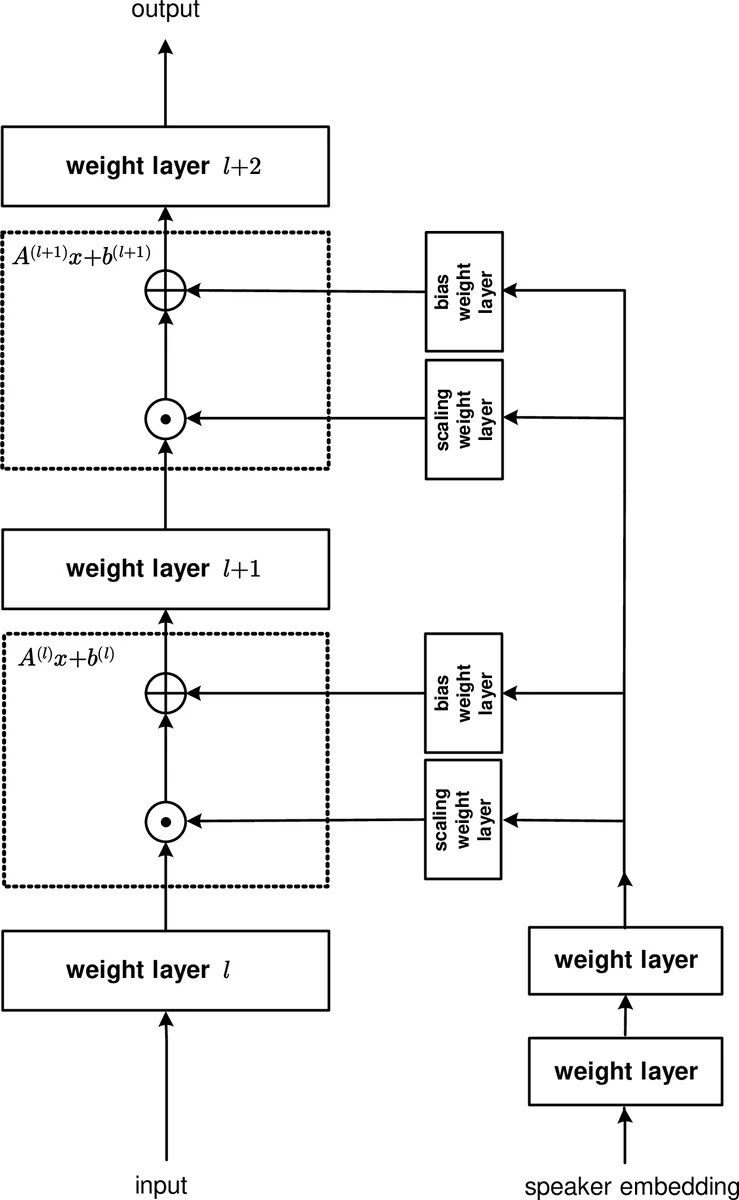
이 연구는 화자 변동성을 내부 표현 수준에서 직접 보정하려는 시도로, 두 개의 신경망—메인 네트워크와 제어 네트워크—을 동시에 학습한다는 점이 핵심이다. 메인 네트워크는 전통적인 DNN, CNN, 혹은 RNN(LSTM) 형태로 음성 인식 모델을 담당하고, 제어 네트워크는 화자 임베딩(e(s), 여기서는 100차원 i‑vector)을 받아 각 선택된 은닉층 l에 대해 스케일링 벡터 a_l과 바이어스 벡터 b_l을 생성한다. 이 변환은 ˆx(s)=a_l⊙x(s)⊕b_l 형태의 요소별 곱·덧 연산으로 구현되며, a_l은 시그모이드 활성화(양수 보장), b_l은 tanh 활성화(양·음 모두 허용)로 제한한다. 이렇게 하면 화자마다 고유한 선형 변환이 적용돼, 은닉층 출력이 “표준화된” 내부 특징 공간으로 매핑된다.
제어 네트워크는 공유된 하위 레이어(입력 차원 100 → 256 → 512 → 1024 등)를 거쳐, 마지막에 각각 스케일링·바이어스 전용 출력 레이어로 분기한다. 이는 파라미터 효율성을 높이며, 여러 은닉층에 동일한 저차원 임베딩을 기반으로 고차원 변환을 학습하도록 돕는다. 학습은 전체 시스템을 하나의 그래프로 보고 교차 엔트로피 손실을 최소화하는 SGD(미니배치, 256 또는 128)로 진행한다.
실험은 Babel(스와힐리·조지아)와 Switchboard(300h, 2000h) 두 데이터셋에서 수행되었다. Babel에서는 5층 DNN에 4개의 SAT 레이어를 삽입했으며, i‑vector를 입력에 추가한 기본 모델 대비 WER이 0.51.1% 절감되었다. 특히 스케일링만 적용한 “게이팅”보다 전체 스케일·바이어스 변환이 더 큰 이득을 보였다. Switchboard에서는 양방향 LSTM(15층) 모델에 적용했으며, 4층 LSTM에서 i‑vector 기반 화자 인식 개선(≈0.71.0% 절감) 위에 SAT를 추가하면 추가 0.10.5% 절감 효과가 나타났다. sMBR 순차 학습 단계에서도 SAT가 지속적으로 WER을 낮추어, 최종 5층 LSTM 모델은 fmllr+ivec+sAT 구성에서 SWB 10.2%, CH 18.0%를 기록했다(기준 10.3%/18.5%).
핵심 인사이트는 다음과 같다. ① 화자 임베딩을 직접 변환 파라미터로 활용하면, 입력 특성에만 의존하는 기존 방식보다 내부 표현을 보다 효과적으로 정규화할 수 있다. ② 요소별 선형 변환(스케일+바이어스)은 단순 스케일링보다 풍부한 적응 능력을 제공한다. ③ 제어 네트워크의 공유 레이어 설계는 파라미터 수를 억제하면서도 고차원 변환을 학습하게 해, 데이터 희소성 문제를 완화한다. ④ 다양한 네트워크 구조(DNN, LSTM)와 레이어 깊이에 적용 가능하며, 특히 깊은 LSTM에서 하위 레이어에만 SAT를 적용하는 것이 효율적이다. ⑤ 최종 성능 향상은 기존 i‑vector 기반 화자 인식 기술을 보완하는 형태로, 실용적인 대규모 LVCSR 시스템에 바로 적용할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기