일상 대화 데이터셋
초록
DailyDialog는 일상 생활에서 일어나는 13,118개의 다중 턴 대화를 모아 만든 고품질 영어 데이터셋이다. 인간이 직접 작성한 문장으로 잡음이 적고, 평균 8턴, 15단어 정도의 길이를 가진다. 각 발화는 4가지 대화 행위(정보제공, 질문, 지시·제안, 수락·거절)와 7가지 감정(분노, 혐오, 공포, 행복, 슬픔, 놀람, 기타)으로 라벨링되었다. 데이터는 주제별(관계, 일상, 직장 등)로 구분되며, 질문‑정보, 지시‑수락 등 자연스러운 양방향 대화 흐름을 포함한다. 논문은 기존의 검색 기반·생성 기반 모델들을 평가하고, DailyDialog가 대화 시스템 연구에 유용한 벤치마크임을 입증한다.
상세 분석
본 논문은 대화 시스템 연구에 필요한 데이터의 품질 문제를 해결하고자 DailyDialog라는 새로운 다중 턴 대화 코퍼스를 제시한다. 먼저 데이터 수집 단계에서 영어 학습용 웹사이트를 크롤링하여 인간이 직접 작성한 일상 대화를 확보했으며, 중복 제거와 자동 맞춤법 교정 과정을 거쳐 13,118개의 대화를 정제하였다. 이때 평균 7.9턴, 14.6단어/발화라는 짧고 집중된 대화 구조를 유지함으로써, 기존 Switchboard(150턴 이상)나 OpenSubtitles(1,000턴 이상)와 달리 모델 학습에 효율적인 길이를 제공한다.
라벨링 측면에서는 두 축, 즉 대화 행위와 감정을 각각 ISO 24617‑2와 Ekman의 ‘Big Six’를 기반으로 4가지 의도와 7가지 감정으로 정의하였다. 의도 라벨은 Inform, Question, Directive, Commissive 로 구분되어 정보 전달과 행동 협상의 흐름을 명확히 드러낸다. 감정 라벨은 Anger, Disgust, Fear, Happiness, Sadness, Surprise, Other 로 구성되어, 일상 대화에서 감정 표현이 얼마나 빈번히 등장하는지를 정량화한다. 라벨링 작업은 3명의 전문가가 78.9%의 상호주관적 일치를 달성했으며, 다수결 원칙을 적용해 최종 라벨을 확정하였다.
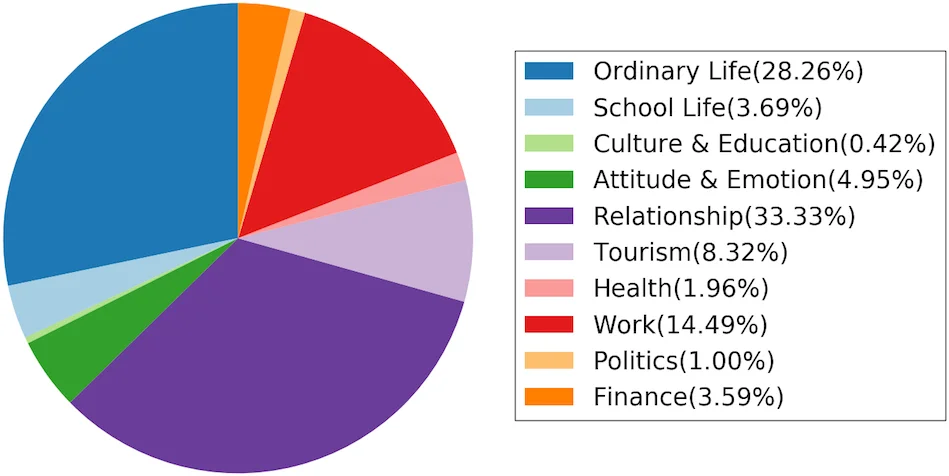
통계 분석에서는 대화 주제가 10가지 카테고리(관계, 일상, 직장 등)로 분포하고, 가장 큰 비중을 차지하는 것이 관계(33.33%)와 일상(28.26%)임을 확인한다. 또한 대화 행위 간 전이 확률을 조사한 결과, Question‑Inform, Directive‑Commissive와 같은 양방향 흐름이 빈번히 나타나며, 이는 기존 QA형 데이터셋이나 일방적 포스트‑리플라이 데이터와 차별화되는 특징이다. 특히 두 가지 복합 흐름 패턴(정보 제공 후 질문 전환, 제안‑제안‑수락)도 발견되어, 인간 대화의 자연스러운 전환 메커니즘을 모델링하는 데 유용한 정보를 제공한다.
평가 실험에서는 임베딩 기반·특징 기반 검색 모델과 Seq2Seq 기반 생성 모델, 그리고 의도·감정 라벨을 활용한 조건부 생성 모델을 DailyDialog에 적용하였다. 결과는 기존 데이터셋에 비해 평균 응답 적합도와 감정 일치도가 향상되었으며, 특히 라벨 정보를 활용한 모델이 감정적 일관성을 유지하는 데 유리함을 보여준다. 이는 DailyDialog가 대화 행위와 감정 제어가 필요한 고급 대화 시스템 연구에 적합한 벤치마크임을 시사한다.
요약하면, DailyDialog는 고품질, 라벨링된 다중 턴 일상 대화 데이터로, 대화 흐름, 주제 다양성, 감정 표현을 체계적으로 포함하고 있어, 대화 행위 인식, 감정 인식, 응답 생성 등 다양한 하위 과제에 활용될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기