경찰 사망 사건 자동 추출을 위한 원격 감독 기반 엔터티‑이벤트 모델
초록
본 논문은 뉴스 기사에서 경찰에 의해 사망한 시민의 이름을 자동으로 추출하는 새로운 NLP 과제를 제시한다. 저자들은 2016년 미국 뉴스 데이터를 수집해 공개 데이터셋을 구축하고, 명명된 엔터티와 문장을 이용해 ‘대상’ 토큰을 마스킹한 뒤 로지스틱 회귀와 합성곱 신경망 기반의 멘션 레벨 분류기를 학습한다. 원격 감독(distant supervision)과 EM 알고리즘을 결합한 잠재적 이산(disjunction) 모델을 통해 멘션 예측을 엔터티 수준 확률로 집계한다. 실험 결과, 기존 오프‑더‑쉘프 이벤트 추출기보다 높은 AUPRC를 달성했으며, 가디언 “The Counted” 데이터베이스에 포함되지 않은 39명의 희생자를 추가로 발견하였다.
상세 분석
이 연구는 사회적 파급력이 큰 ‘경찰 사망 사건’이라는 특수 도메인을 NLP에 적용함으로써 두 가지 중요한 기술적 기여를 한다. 첫째, 저자들은 크로스‑도큐먼트 엔터티‑이벤트 추출이라는 프레임워크를 명확히 정의한다. 여기서 엔터티는 사람 이름이며, 이벤트는 “경찰에 의해 사망”이라는 단일 이진 관계이다. 기존의 사건 추출 연구와 달리, 이 작업은 다중 멘션을 가진 엔터티에 대해 ‘어떤 멘션이라도 사건을 기술하면 해당 엔터티는 사건에 포함된다’는 논리적 디스정션(OR) 규칙을 적용한다. 이는 Pearl의 noisy‑or 모델을 수식적으로 구현한 것으로, 멘션‑레벨 확률을 곱셈적으로 결합해 엔터티‑레벨 사망 확률을 계산한다(식 6).
두 번째 기여는 원격 감독을 활용한 학습 전략이다. 금전적·시간적 제약으로 인해 사건에 대한 직접 라벨링이 불가능한 상황에서, 저자들은 ‘Fatal Encounters’ 데이터베이스를 금빛(gold) 엔터티 집합으로 사용한다. ‘Hard’ 라벨링은 이름 일치 혹은 이름·위치 일치를 통해 멘션에 긍정 라벨을 부여한다. 그러나 실제 문맥에서는 이름만 일치해도 사건과 무관한 언급이 다수 존재함을 확인하고, 라벨 노이즈 문제를 완화하기 위해 ‘Soft’ 라벨링, 즉 EM 기반의 다중 인스턴스 학습(MIL)을 도입한다. 초기 파라미터는 Hard 라벨링으로 학습하고, 이후 E‑step에서 멘션‑레벨 후방 확률 q(z_i)를 계산한다. 이 확률은 멘션이 실제 사건을 기술할 확률을 ‘노이즈‑오르’ 제약 하에 부드럽게 조정한다. M‑step에서는 q(z_i)를 가중치로 사용해 로지스틱 회귀(LR)와 합성곱 신경망(CNN) 두 모델을 최대우도 추정한다.
특징 설계 측면에서, LR은 의존구조 경로, POS, 단어 등 3‑그램 형태의 텍스트 특징을 활용한다. CNN은 임베딩 레이어와 다중 필터 크기를 통해 문맥 정보를 자동 추출한다. 두 모델 모두 ‘TARGET’ 토큰을 삽입해 대상 인물에 대한 정보를 명시적으로 강조한다.
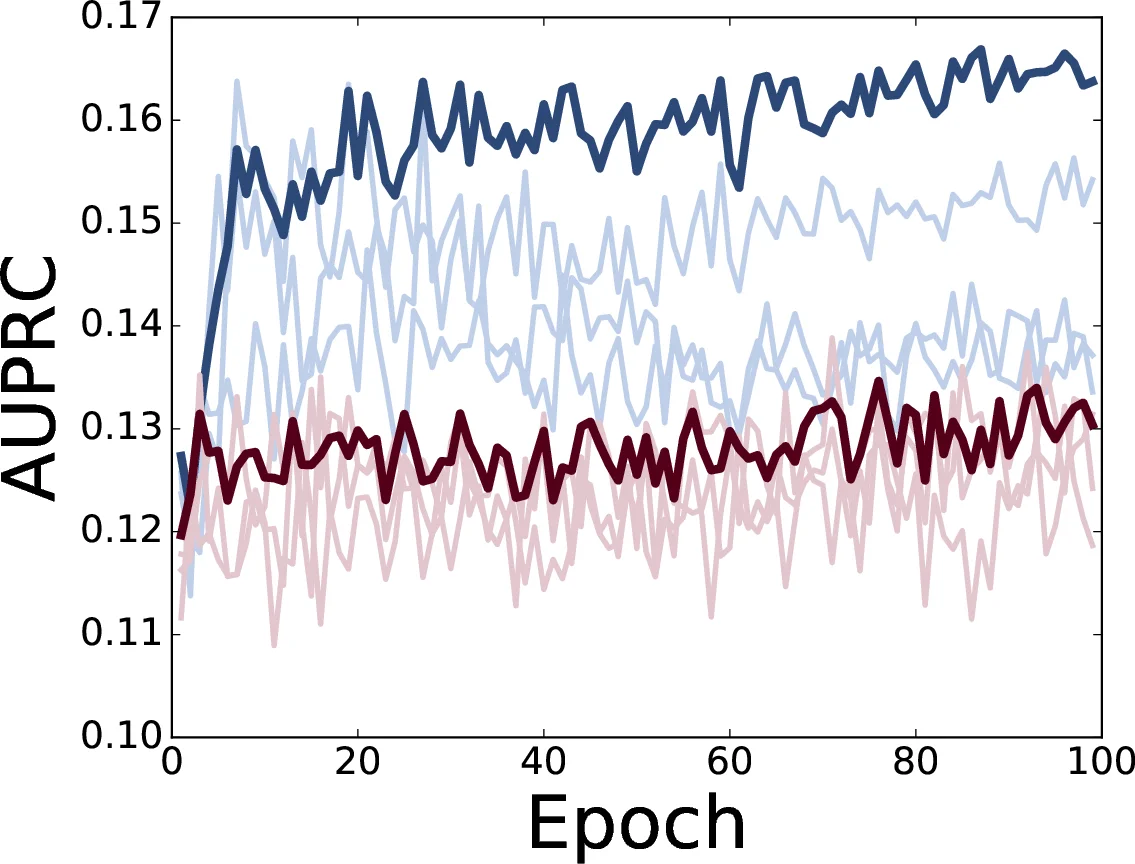
실험에서는 2016년 1‑8월(학습)과 9‑12월(테스트) 구간을 나누어 약 1백만 개의 뉴스 문서를 처리했으며, NER을 통해 약 130k 멘션을 추출했다. 키워드 필터링(‘police’, ‘kill’ 등)으로 99%의 멘션을 제거했지만, 긍정 엔터티 재현율은 0.57까지 유지했다. 평가 지표는 AUPRC이며, Soft‑LR(EM) 모델이 정규화 파라미터 C=1e‑1일 때 0.18의 AUPRC를 기록, 기존 오프‑더‑쉘프 시스템(예: OpenIE, Stanford Event Extractor)보다 현저히 우수했다. 또한, 모델이 제안한 후보 중 39명은 가디언 데이터베이스에 없었으며, 이는 자동화된 시스템이 인간 수작업보다 빠르게 새로운 희생자를 발견할 가능성을 시사한다.
한계점으로는 이름 매칭에 의존한 코어퍼런스 해결 방식, 미국 뉴스에 편중된 데이터 수집, 그리고 라벨 노이즈가 여전히 존재한다는 점을 들 수 있다. 향후 연구에서는 보다 정교한 엔터티 정규화, 다국어·다문화 데이터 확장, 그리고 사건 유형(예: 과잉진압, 무력 사용) 구분을 위한 다중 라벨 모델링이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기