빔 서치를 연속적으로 완화한 신경 시퀀스 모델 학습 방법
초록
본 논문은 전통적인 교차 엔트로피(CE) 학습이 빔 서치 디코딩과 불일치해 성능 저하를 일으키는 문제를 해결하고자, 빔 서치 과정을 연속적으로 근사하는 새로운 손실 함수를 제안한다. 연속적인 top‑k‑argmax와 피크드‑소프트맥스를 이용해 미분 가능하게 만든 뒤, 최종 평가 손실(예: 해밍 손실)을 직접 최소화한다. 실험 결과, NER과 CCG 슈퍼태깅 두 과제에서 기존 CE‑기반 그리디 및 빔 디코딩보다 현저히 높은 정확도를 달성한다.
상세 분석
이 연구는 시퀀스‑투‑시퀀스 모델의 학습 목표와 테스트 시 사용되는 탐색 알고리즘 사이의 불일치를 근본적으로 고치려는 시도이다. 전통적인 교차 엔트로피(CE) 학습은 각 타임스텝에서 정답 토큰을 확률적으로 최대화하도록 모델을 훈련하지만, 실제 추론 단계에서는 빔 서치와 같은 전역 탐색 전략을 사용한다. 빔 서치는 여러 후보 시퀀스를 동시에 유지하면서 최적 경로를 찾지만, CE‑학습은 이러한 전역 구조를 고려하지 않기 때문에 빔 크기가 커질수록 오히려 성능이 떨어지는 현상이 보고되었다.
논문은 이러한 문제를 “직접 손실(direct loss)”이라는 개념으로 정의한다. 즉, 입력 x에 대해 모델 M(θ)으로 빔 서치를 수행한 후 얻은 최종 시퀀스 ŷ와 정답 y* 사이의 평가 손실 L(ŷ, y*)를 직접 최소화한다. 하지만 빔 서치 과정은 argmax와 top‑k 선택이라는 이산 연산을 포함하므로 손실 함수가 불연속적이며, 미분이 불가능해 기존의 경사 하강법을 적용할 수 없다.
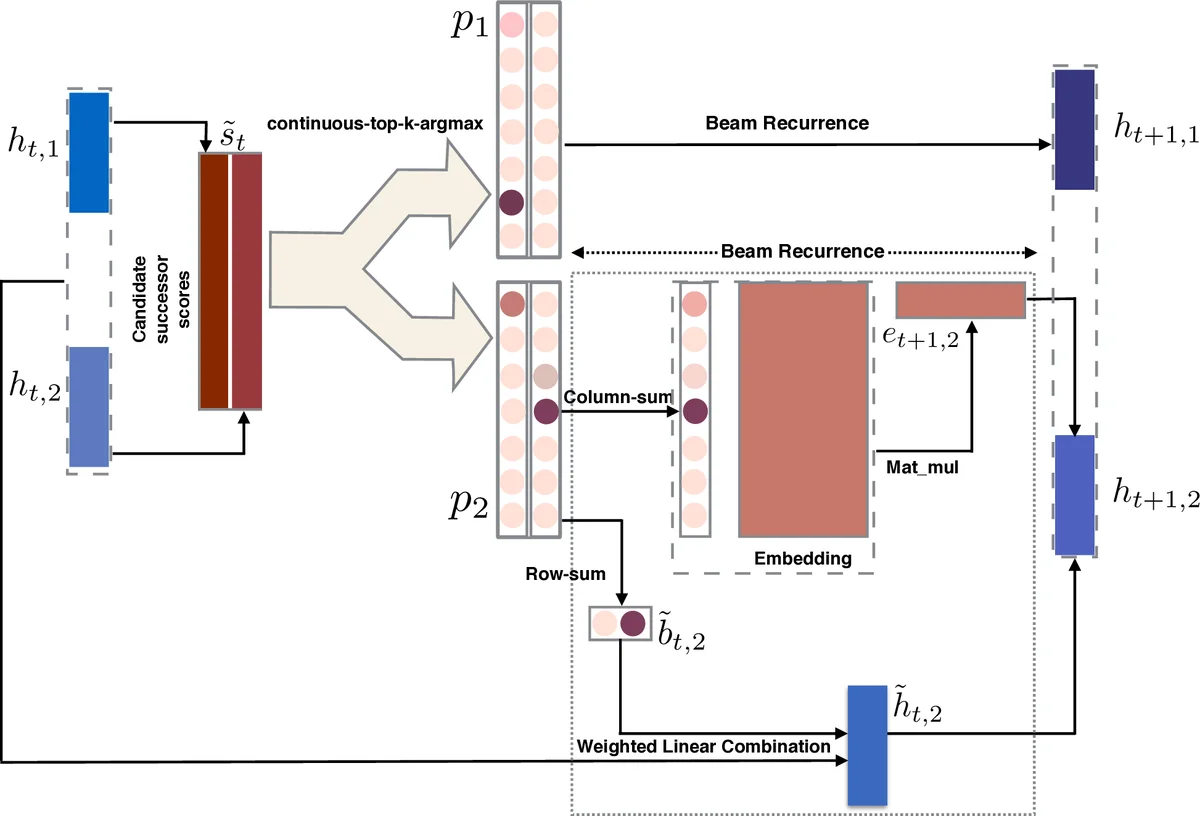
이를 해결하기 위해 저자들은 두 단계의 연속적 근사를 제시한다. 첫 번째는 argmax를 온도 파라미터 α를 갖는 피크드‑소프트맥스( peaked‑softmax )로 대체하는 것이다. α가 무한대로 커지면 피크드‑소프트맥스는 실제 argmax와 동일해지지만, 유한한 α에서는 부드러운 확률 분포를 제공해 미분 가능하게 만든다. 두 번째는 top‑k‑argmax를 반복적인 피크드‑소프트맥스 연산으로 구현한다. 구체적으로, 점수 행렬 ˜s∈ℝ^{k×|V|}에 대해 가장 큰 값 m₁을 찾고, (s−m₁)²의 부정값에 피크드‑소프트맥스를 적용해 첫 번째 후보의 확률 분포 p₁을 만든다. 이후 m₂, m₃ … 를 순차적으로 구해 p₂, p₃ … 를 얻는다. 이렇게 하면 각 p_i는 i번째 최고 점수에 집중된 연속적 “soft backpointer”와 “soft candidate”를 제공한다.
연속적 빔 서치 알고리즘(Algorithm 3)은 위의 연속적 top‑k‑argmax를 이용해 각 타임스텝에서 다음과 같은 과정을 수행한다. 1) 현재 빔 상태 h_{t,i}와 모든 어휘 v에 대해 점수 ˜s_{t}
댓글 및 학술 토론
Loading comments...
의견 남기기