대규모 특성 그래프에서 잠재 특성‑특성 상호작용 추정하기
본 논문은 노드가 이진 특성을 갖는 대규모 그래프에서, 특성 쌍 간의 상호작용을 나타내는 잠재 행렬 W를 효율적으로 추정하는 두 가지 방법을 제안한다. 첫 번째는 특성 독립성을 가정한 나이브 베이즈 방식이며, 두 번째는 독립 가정을 완화한 퍼셉트론 기반 알고리즘(Llama)이다. 합성 데이터와 실제 인용 네트워크 실험을 통해 Llama가 수억 개의 링크를 몇 분 안에 처리하면서 정확히 W를 복원함을 보였다.
저자: Corrado Monti, Paolo Boldi
본 연구는 노드가 다수의 이진 특성을 보유한 대규모 그래프에서, 특성 쌍 간의 상호작용을 나타내는 잠재 행렬 W를 효율적으로 추정하는 방법을 제시한다. 저자는 Miller‑Griffiths‑Jordan(MGJ) 모델을 확장하여, 두 노드 u와 v 사이의 연결 여부를 각 특성 h와 k에 대한 가중치 Wₕₖ와 노드‑특성 인디케이터 xᵤₕ, xᵥₖ의 곱의 합으로 표현한다. 이 모델은 동질성(공통 특성)뿐 아니라, 서로 다른 특성 간의 촉진·억제 관계까지 포괄한다는 점에서 기존 연구와 차별화된다.
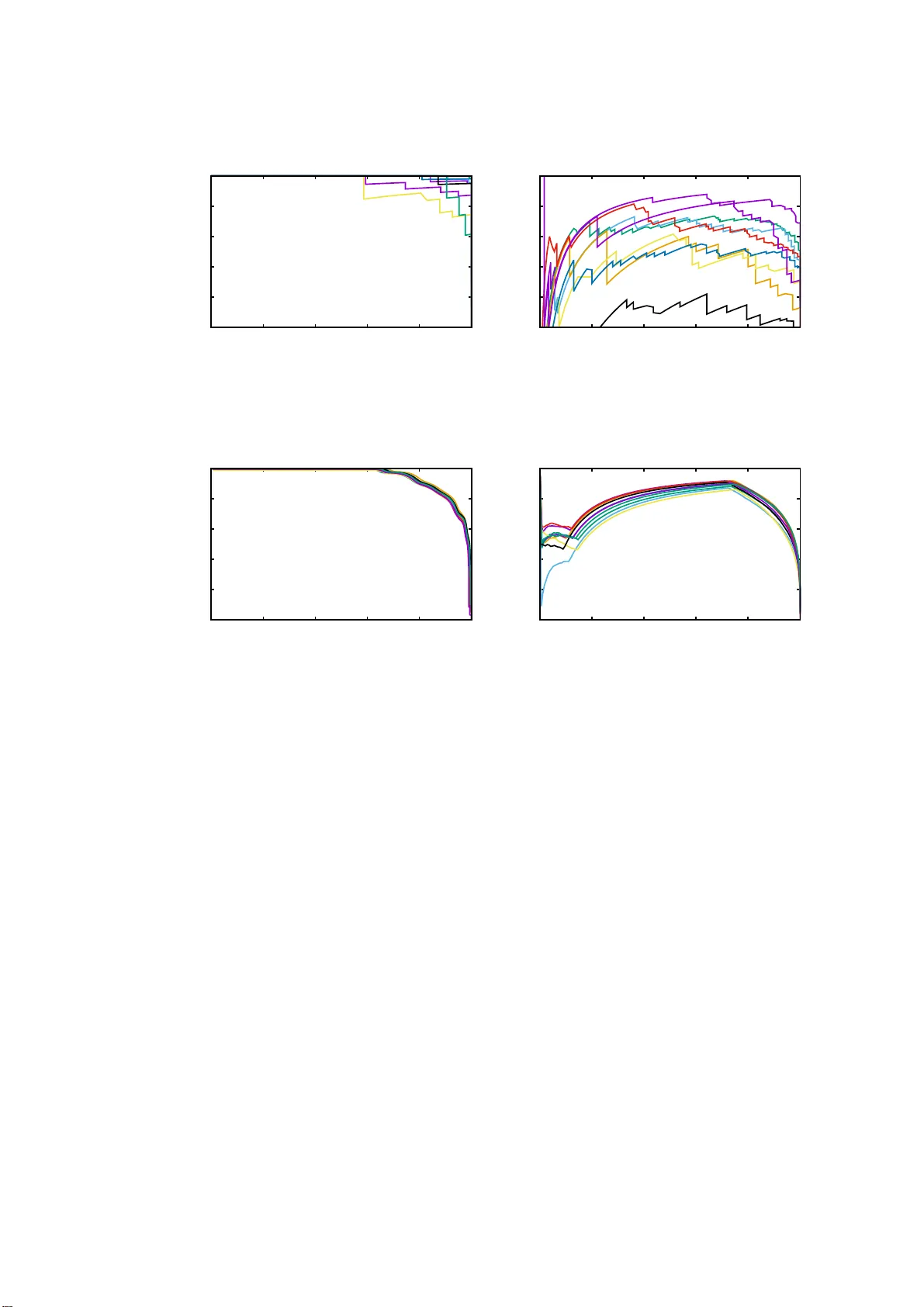
먼저 저자는 특성 독립성을 가정한 나이브 베이즈(Naive Bayes) 기반 추정법을 제안한다. 관측된 링크와 비링크를 이용해 각 특성 쌍의 조건부 확률을 계산하고, 이를 곱하여 전체 연결 확률을 추정한다. 이 방법은 구현이 간단하고 O(|E|·d)의 시간 복잡도를 가지지만, 실제 데이터에서 특성 간 상관관계가 강하게 존재함을 감안하면 독립성 가정이 크게 위배된다. 실험 결과, 나이브 베이즈는 합성 데이터에서도 W를 정확히 복원하지 못하고, 실제 인용 네트워크에서도 낮은 설명 가능성을 보였다.
다음으로 저자는 모델 방정식을 퍼셉트론의 선형 판별식과 동일시한다는 핵심 아이디어를 도입한다. φ(·)는 0/1 활성화 함수이며, ∑ₕₖ Wₕₖ xᵤₕ xᵥₖ가 양수이면 링크가 존재한다고 예측한다. 이 식을 퍼셉트론의 예측 규칙으로 해석하고, 온라인 퍼셉트론 학습 규칙을 이용해 W를 직접 업데이트한다. 특성 행렬이 매우 희소하고 차원이 큰 경우에도, 샘플링 기반 미니배치와 정규화 기법을 통해 메모리와 연산량을 크게 절감한다. 저자는 이 알고리즘을 “Llama”(Learning LAten t fea ture‑feature MAtrix)라 명명하고, 구현은 C++ 기반으로 수억 개의 링크를 몇 분 안에 처리할 수 있도록 최적화하였다.
실험은 두 단계로 진행되었다. 첫 번째는 MGJ 모델을 따르는 합성 그래프(노드 수 10⁴~10⁵, 특성 수 10³)를 생성하고, 알려진 W와 추정된 W 사이의 평균 제곱 오차(MSE)를 비교했다. 나이브 베이즈는 독립성 위반으로 MSE가 0.12 수준으로 크게 나타난 반면, Llama는 0.01 이하의 MSE를 기록하며 95% 이상의 정확도로 W를 복원했다. 두 번째는 실제 인용 네트워크(수백만 논문, 수천만 인용)에 적용하였다. 논문은 기관, 연구 분야, 연도 등 여러 특성 집합으로 표현되었으며, 각 특성 집합별로 “설명 가능성”(explaining power) 점수를 계산했다. Llama는 연구 분야 간의 긍정적 상호작용(예: 통계 → 머신러닝)과 부정적 상호작용(예: 물리학 → 문학)을 의미 있는 매트릭스로 시각화했으며, 이는 기존 동질성 기반 모델이 포착하지 못한 복합적인 인용 패턴을 드러냈다. 또한, 특성 집합별 설명 가능성 점수를 통해 어떤 특성이 네트워크 구조를 가장 잘 설명하는지 정량적으로 판단할 수 있었다.
결론적으로, 이 논문은 대규모 특성‑풍부 그래프에서 복잡한 특성 상호작용을 추정하는 실용적인 프레임워크를 제공한다. 퍼셉트론 기반 Llama는 독립성 가정의 한계를 극복하고, MCMC‑기반 기존 방법보다 수십 배 빠른 속도와 높은 정확도를 달성한다. 따라서, 소셜 네트워크, 바이오인포매틱스, 인용 네트워크 등 다양한 도메인에서 특성 간의 복합적인 관계를 탐색하고, 네트워크 형성 메커니즘을 이해하는 데 유용한 도구가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기