다중스케일 시계열 데이터를 위한 계층적 변분 오토인코더와 무감독 표현 분리
초록
본 논문은 연속적인 음성 데이터를 대상으로, 시퀀스 수준과 세그먼트 수준의 정보를 각각 다른 잠재 변수에 할당하는 계층적 변분 오토인코더(FHVAE)를 제안한다. 시퀀스‑종속 사전분포와 시퀀스‑독립 사전분포를 이용해 말하기자 특성, 잡음 등 전역 속성과 음소·음절 등 국부 속성을 분리하고, 이를 통해 화자 변환·노이즈 제거와 같은 변형이 가능함을 시각적으로 보여준다. 또한 화자 검증에서 i‑vector를 능가하고, 잡음이 섞인 환경에서 자동음성인식(ASR) 성능을 최대 35% 향상시키는 정량적 결과를 제시한다.
상세 분석
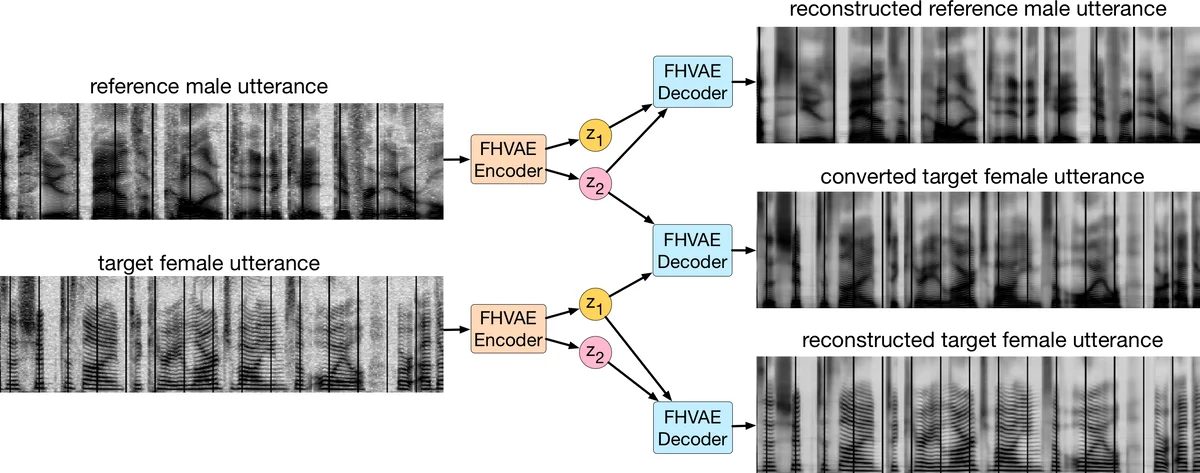
이 연구는 시계열 데이터가 내재하는 다중스케일 특성을 명시적으로 모델링한다는 점에서 의미가 크다. 기존 VAE 기반 접근법은 전체 시퀀스를 하나의 잠재 공간에 매핑하는 경우가 많아, 전역적인 변동(예: 화자, 채널)과 국부적인 변동(예: 음소, 억양)을 구분하기 어렵다. 저자들은 이를 해결하기 위해 두 종류의 잠재 변수 z₁(세그먼트‑레벨)와 z₂(시퀀스‑레벨)를 도입하고, 각각에 서로 다른 사전분포를 부여한다. 구체적으로 z₂는 시퀀스‑특정 s‑벡터 μ₂를 중심으로 하는 가우시안 사전(p(z₂|μ₂))을 갖고, μ₂ 자체도 평균이 0인 가우시안 사전(p(μ₂))을 가진다. 반면 z₁은 전역적으로 동일한 표준 정규분포(p(z₁))를 사용한다. 이러한 구조는 z₂가 동일 시퀀스 내에서 서로 가깝게, 서로 다른 시퀀스 간에는 멀어지도록 강제함으로써 전역 속성을 캡처하도록 만든다.
학습 과정에서 변분 하한을 세그먼트 단위로 분해해 전체 시퀀스를 한 번에 처리하지 않아도 되도록 설계했으며, 이는 매우 긴 시퀀스에도 확장성을 제공한다. 또한, μ₂가 모든 시퀀스에 대해 0으로 수렴하는 ‘트리비얼’ 솔루션을 방지하기 위해 z₂를 이용해 시퀀스 인덱스를 예측하는 판별적 목표(log p(i|z₂))를 추가한다. 이 판별적 손실은 가중치 α와 함께 변분 하한에 결합되어, z₂가 실제로 시퀀스‑레벨 정보를 담도록 유도한다.
네트워크 아키텍처는 인코더와 디코더 모두 LSTM 기반의 시퀀스‑투‑시퀀스 구조를 사용한다. z₂는 전체 세그먼트를 입력받은 LSTM의 최종 은닉 상태에서 추정되고, z₁은 z₂와 함께 입력된 LSTM을 통해 추정된다. 디코더는 z₁과 z₂를 결합한 입력을 받아 매 타임스텝마다 프레임을 재구성한다. 재파라미터화 기법을 통해 샘플링 과정을 미분 가능하게 만든 점도 주목할 만하다.
실험에서는 TIMIT과 Aurora‑4 두 음성 코퍼스를 사용했으며, 정량적 평가는 화자 검증(EER)과 ASR(WER) 두 축에서 수행되었다. 무감독 화자 검증에서 2.38%의 EER, 라벨이 있는 경우 1.34%의 EER을 기록해 기존 i‑vector 기반 시스템을 능가했다. 또한, 잡음이 섞인 테스트 환경에서 사전 학습된 모델에 비해 최대 35%까지 WER를 감소시켰다. 정성적 실험에서는 z₁을 교체하면 음소·내용은 유지하면서 화자·노이즈 특성만 바뀌는 변환이 가능함을 시각·청각적으로 확인했다.
이 모델의 강점은 (1) 명시적인 다중스케일 구조로 해석 가능한 잠재 공간을 제공한다, (2) 판별적 목표를 통해 사전분포가 무의미해지는 현상을 방지한다, (3) 세그먼트‑레벨 학습으로 긴 시퀀스에도 효율적으로 적용 가능하다, (4) 실제 음성 처리 과제에서 성능 향상을 입증했다는 점이다. 반면 한계점으로는 (①) 현재는 두 단계(시퀀스·세그먼트)만 고려했으며, 더 복잡한 계층(예: 세션‑레벨)으로 확장하려면 추가적인 설계와 계산 비용이 필요하다, (②) 모든 잠재 변수와 사전이 가우시안 형태에 제한돼 비선형·비가우시안 특성을 충분히 포착하지 못할 가능성이 있다, (③) 판별적 손실의 가중치 α 선택이 성능에 민감하며, 최적값을 찾기 위한 별도 검증이 필요하다.
전반적으로, 이 논문은 시계열 데이터의 다중스케일 특성을 활용한 무감독 표현 학습에 새로운 패러다임을 제시하며, 음성 분야뿐 아니라 영상·텍스트 등 다양한 연속 데이터에도 적용 가능성을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기