노이즈 대비 추정으로 언어 모델 성능 극대화
초록
본 논문은 대규모 어휘를 갖는 신경 언어 모델에서 정규화 비용을 피하기 위해 노이즈 대비 추정(NCE)을 활용한다. 학습률 스케줄인 ‘search‑then‑converge’, 드롭아웃 비율, 가중치 초기화 범위 등 핵심 하이퍼파라미터를 체계적으로 탐색·조정함으로써, 기존 소프트맥스 기반 모델을 능가하는 단일 모델 성능을 PTB 벤치마크에서 달성하였다.
상세 분석
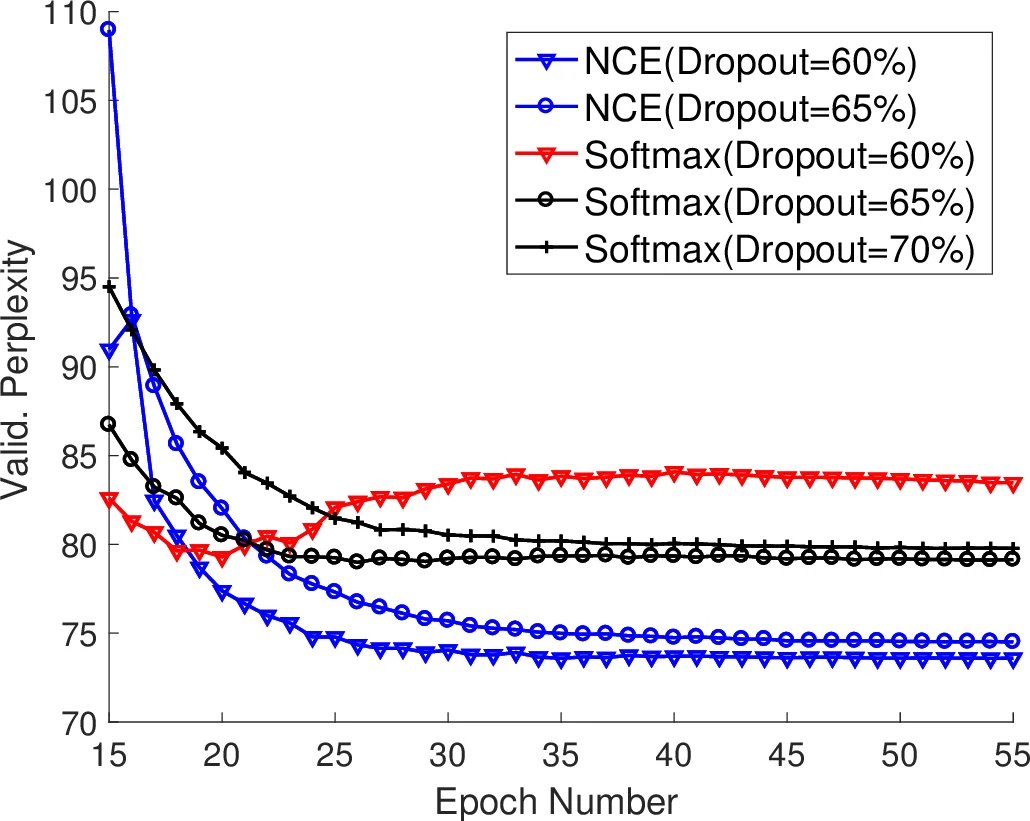
이 연구는 NCE가 이론적으로는 정규화 상수를 추정하지 않아도 되는 장점을 가지고 있음에도 불구하고, 실제 언어 모델링에서는 소프트맥스에 비해 성능이 뒤처진다는 기존 평가와는 달리, 하이퍼파라미터 튜닝이 성능 격차를 해소한다는 점을 강조한다. 가장 핵심적인 기여는 ‘search‑then‑converge’ 학습률 스케줄을 도입한 것이다. 초기 단계(검색 기간)에서는 일정한 학습률 η₀를 유지해 파라미터가 넓은 최적화 공간을 탐색하도록 하고, τ 에포크 이후에는 η(t)=η₀·(1+max(t−τ,0))⁻¹ 로 감소시켜 수렴을 촉진한다. 저자들은 τ 를 전체 학습 에포크의 1~2/3 사이로 설정하면 NCE가 특히 민감하게 반응한다는 실험적 근거를 제시한다.
또한 가중치 초기화 전략에서도 기존 Glorot 초기화보다 작은 분산을 갖는 균등 분포를 사용함으로써, NCE가 학습 초기에 과도한 출력 스케일링을 방지하고 안정적인 로그우도 추정에 기여한다는 점을 발견했다. 드롭아웃 비율 역시 NCE 학습에서 과적합을 억제하는 중요한 요인으로, 적절한 비율(예: 0.2~0.5) 설정이 모델 일반화에 크게 이바지한다.
실험에서는 Penn Treebank(10k 어휘) 데이터를 사용해 2‑layer LSTM 기반 언어 모델을 구현하였다. 소프트맥스와 NCE를 동일한 네트워크 구조에 적용했으며, NCE 모델은 위에서 제시한 하이퍼파라미터 조합을 적용했다. 결과적으로 NCE 모델은 perplexity 55.3을 기록, 기존 최첨단 단일 모델(softmax 기반)인 57.3보다 우수했다. 특히, NCE는 학습 시간도 30% 이상 단축되어 실용적인 이점을 제공한다.
이 논문은 NCE가 “통계적으로 일관적”이라는 이론적 강점을 실제 대규모 언어 모델에 적용할 때, 학습률 스케줄링과 초기화·정규화 전략이 결정적인 역할을 한다는 실증적 증거를 제공한다. 따라서 NCE는 단순히 소프트맥스의 근사 대안이 아니라, 적절히 튜닝될 경우 더 나은 지역 최적점을 찾을 가능성이 있는 강력한 최적화 프레임워크로 재평가될 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기