집계 규모에 따른 전력 부하 예측 정확도 스케일링 법칙
본 논문은 전력 부하를 다양한 집계 수준으로 묶을 때 예측 정확도가 어떻게 변하는지를 설명하는 경험적 스케일링 법칙을 제시한다. 개인 가구·소규모 사업체의 1시간·다시간·일일 예측을 여러 모델(SARMA, SVR, FFNN 등)로 수행하고, 평균 부하와 오차 지표(CV, MAPE) 사이의 관계를 이론적 편향‑분산 분석과 실험적 집계 오류 곡선(Aggregation Error Curve, AEC)으로 검증한다. 결과는 부하가 일정 수준 이하에서는…
저자: Raffi Sevlian, Ram Rajagopal
본 논문은 전력 부하 예측 정확도가 고객 집계 규모에 따라 어떻게 변하는지를 정량적으로 규명하고, 이를 활용한 벤치마킹 프레임워크를 제시한다. 서론에서는 분산형 에너지 자원의 급증과 스마트 미터 보급으로 인해 배전 수준에서의 짧은 시간대(1시간~1일) 부하 예측 필요성이 강조된다. 기존 연구는 주로 변전소·전송 수준(수십 GW)에서의 예측에 초점을 맞췄으며, 가구·소규모 사업체 수준에서는 예측 오차가 15~30%에 달한다는 점을 지적한다. 이러한 격차를 메우기 위해 저자들은 “집계 규모에 따른 예측 정확도 스케일링 법칙”을 제안한다.
문헌 검토에서는 전통적인 SARMA, 신경망, 서포트 벡터 회귀 등 다양한 단기 부하 예측 방법을 소개하고, 최근 개별·중간 규모 집계에 대한 실험적 결과들을 정리한다. 특히, 기존 연구들은 1 000~1 000 명 수준의 작은 집합에 국한돼 대규모(10⁵명 이상)에서의 스케일링 특성을 충분히 탐구하지 못했다는 점을 강조한다.
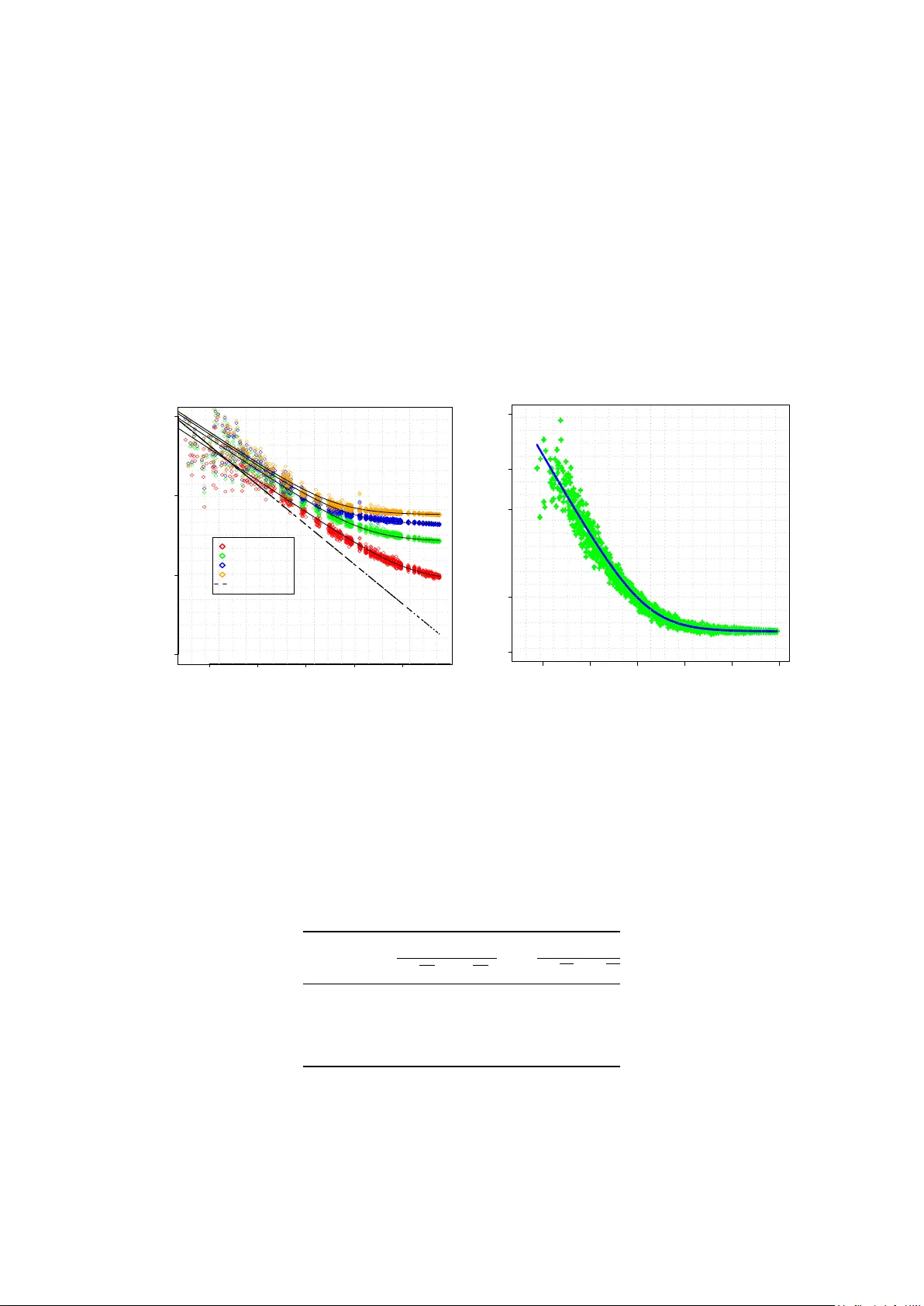
본 연구의 핵심 모델링은 개별 소비 시계열 xₙ(t) 를 평균 Wₙ 과 변동 σₙ² 를 갖는 독립적인 랜덤 프로세스로 가정하고, 집계 부하 x_A(t)=∑_{n∈A}xₙ(t) 의 평균 W_A 를 정의한다. 예측기 \hat{x}_A(t) 에 대해 변동계수(CV)와 평균절대백분율오차(MAPE)를 사용해 성능을 평가한다. Theorem 1에 따르면, 동일 평균 부하 W 를 갖는 모든 집합 A 에 대해 기대 CV는
CV(W)=α₀ W^{‑p}+α₁
의 형태를 따른다. 여기서 α₀ 은 집계에 의한 오차 감소 효과, α₁ 은 포화 수준, p 는 실험적으로 1에 근접하도록 조정되는 자유 파라미터이다. p=1이면 전통적인 1/√W 스케일링을 의미한다. 두 구간(스케일링 구간·포화 구간)으로 나뉘어, 작은 W 에서는 α₀/√W 가 α₁보다 커서 오차가 급격히 감소하고, 큰 W 에서는 α₁이 지배해 오차가 일정 수준에 머문다.
실험 데이터는 캘리포니아의 Pacific Gas & Electric(PG&E)에서 제공한 180 k 가구와 150 k 소·중형 사업체의 1년치 전력 사용량(시간 간격)이다. 가구 평균 부하는 1.05 kWh, SMB는 8.94 kWh이며, 각각 4 kWh·180 MWh, 10 kWh·670 MWh 범위의 집계 부하를 생성한다. 집계 프로파일은 무작위 샘플링을 통해 1명부터 100 000명까지 56개의 규모(가구)·43개의 규모(SMB)를 만든다. 각 집계에 대해 다음과 같은 예측 모델을 적용한다: SARMA(1~3차) (M₁~M₃), RBF‑SVR (M₄), 로지스틱 FFNN (M₅), 그리고 “일일 총량+형상” 모델 (M₆). 1시간, 다시간, 일일 예측을 수행하고, 각각 CV와 MAPE를 계산한다.
결과는 모든 모델·예측 지평에 대해 동일한 스케일링 패턴을 보였다. CV‑AEC는 평균 부하가 약 10 kWh(가구)·≈ 100 kWh(SMB) 이하일 때 1/√W에 근접한 감소율을 보였으며, 부하가 약 30 MWh(가구)·≈ 200 MWh(SMB) 수준을 초과하면 CV가 α₁에 수렴해 포화 현상이 나타났다. 이는 추가적인 고객 집계가 예측 정확도에 실질적 이득을 주지 못함을 의미한다. 특히, M₆처럼 부하 형태를 별도로 예측하는 고급 모델에서도 동일한 포화점이 관찰돼, 스케일링 법칙이 모델 독립적임을 확인했다.
논문의 기여는 다음과 같다. 첫째, 편향‑분산 분석을 기반으로 한 경험적 스케일링 법칙을 수학적으로 도출하고, 이를 실제 대규모 스마트 미터 데이터에 적용해 검증하였다. 둘째, Aggregation Error Curve(AEC)라는 벤치마크 도구를 제시해, 새로운 예측 알고리즘이 특정 집계 규모에서 기대할 수 있는 최적 오차를 사전에 추정할 수 있게 했다. 셋째, 다양한 모델·시간 지평에 걸쳐 법칙의 보편성을 입증함으로, 배전 시스템 설계·운영 시 집계 수준에 따른 예측 정확도 한계를 명확히 제시했다.
한계점으로는 개별 소비가 독립적이라는 가정이 현실의 상관관계(예: 동일 날씨·시간대에 동시 변동)를 충분히 반영하지 못한다는 점, 그리고 비대칭적인 MAPE와 같은 지표에 대한 추가 검증이 필요하다는 점을 들 수 있다. 향후 연구는 상관 구조를 포함한 확률적 모델링, 확률적(분포 기반) 예측과의 결합, 그리고 실시간 클러스터링을 통한 동적 집계 규모 최적화 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기