숨은 집단 응집을 드러내는 수치 히스토그램 스코어
초록
본 논문은 이질적인 생물학적 조직 내에서 객체 간 거리 히스토그램을 연속적인 수치(NHS)로 변환하고, 이를 색상 맵으로 시각화하는 방법을 제시한다. NHS 알고리즘은 각 거리 구간에 가중치를 부여해 집합적 응집 정도를 정량화하고, 디지털 병리학에서 지역적 패턴을 드러내는 히트맵을 생성한다. 이를 통해 종양 조직, 바이오필름, 세포 소기관 등에서 숨겨진 집단적 상관관계를 시각·정량적으로 파악할 수 있다.
상세 분석
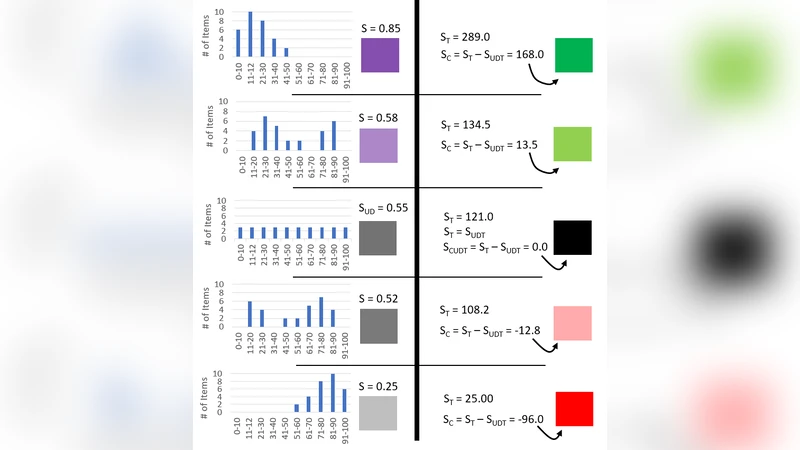
논문은 기존 다변량 분석 기법인 PCA와 MCA가 변수 간 상관관계는 파악하지만, 실제 이미지 상에서 객체들의 공간적 위치 정보를 제공하지 못한다는 한계를 지적한다. 이를 보완하기 위해 저자들은 ‘Numericized Histogram Score(NHS)’라는 새로운 정량화 방식을 고안하였다. NHS는 먼저 이미지 내 모든 객체 쌍 사이의 최단 거리를 계산하고, 이 거리들을 일정한 구간(bin)으로 나누어 히스토그램을 만든다. 각 구간에는 사전 정의된 가중치(w₁, w₂,…, wₙ)를 곱해 가중 히스토그램을 구성하고, 전체 가중합을 전체 객체 수로 정규화하여 0과 1 사이의 연속값을 얻는다. 이 값은 해당 객체가 주변 객체와 얼마나 밀집해 있는지를 나타내는 지표가 된다.
핵심적인 기술적 특징은 다음과 같다. 첫째, 가중치는 거리 순서에 따라 감소하도록 설계되어 가까운 객체에 높은 점수를 부여함으로써 실제 물리적 응집을 강조한다. 둘째, 정규화 과정은 이미지 전체의 밀도 차이를 보정해 서로 다른 샘플 간 비교를 가능하게 한다. 셋째, NHS 값을 색상 스케일에 매핑하면 각 객체가 색상으로 표현된 히트맵이 생성되며, 이는 눈에 보이는 시각적 패턴을 제공한다.
알고리즘의 구현은 파이썬 기반의 이미지 처리 라이브러리(OpenCV, scikit-image)와 수치 연산 패키지(Numpy)를 활용해 비교적 간단히 재현 가능하다. 저자들은 실험적으로 종양 조직 슬라이드와 바이오필름 이미지를 대상으로 NHS 히트맵을 생성했으며, 전통적인 시각 검토에서는 놓치기 쉬운 국소적 고밀도 영역을 명확히 드러냈다. 또한, 이러한 영역을 기준으로 환자군을 재분류했을 때, 임상 결과와의 상관관계가 향상되는 것을 확인하였다.
한계점으로는 거리 계산 비용이 O(N²) 수준으로 객체 수가 많을 경우 연산량이 급증한다는 점이다. 이를 해결하기 위해 KD-Tree나 Ball-Tree와 같은 공간 인덱싱 구조를 도입하거나, 샘플링 기반 근사 방법을 적용할 여지가 있다. 또한, 가중치 함수 선택이 결과에 민감하게 작용하므로, 도메인 별 최적화가 필요하다.
전반적으로 NHS는 정량적 거리 히스토그램을 시각적 열지도로 전환함으로써, 이질적인 조직 내 숨은 집단 응집을 탐지하고, 이를 기반으로 임상·오믹스 데이터와 연계한 다중 분석 파이프라인을 구축할 수 있는 강력한 도구로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기