CPU‑GPU 하이브리드 병렬 솔버로 구현한 대규모 시프트 시스템 해법
초록
본 논문은 복소 시프트가 수천 개에 달하고 다중 우변을 갖는 선형 시스템 (A‑σI)X = B 를 해결하기 위해, 행렬 A와 우변 B를 컨트롤러‑헨시버그 형태로 변환한 뒤, 변환 단계는 CPU‑GPU 혼합 블록 알고리즘으로 수행하고, 변환된 m‑헨시버그‑삼각 시스템을 GPU에서 배치 단위로 동시에 풀어내는 하이브리드 직접 해법을 제안한다. 실험을 통해 기존 CPU 전용 구현 대비 GPU 가속이 DGEMM 수준의 속도 향상을 제공함을 확인한다.
상세 분석
이 연구는 시프트된 선형 시스템을 직접 해법으로 처리할 때, 전통적인 Hessenberg 변환이 시프트마다 순차적으로 수행되어 병렬 활용이 제한된다는 문제점을 짚는다. 이를 해결하기 위해 저자들은 먼저 행렬 A와 우변 B를 컨트롤러‑헨시버그 형태(A는 m‑헨시버그, B는 상삼각)로 변환한다. 변환 과정은 두 단계로 나뉜다. 첫 번째 단계에서는 B에 대한 QR 분해를 CPU에서 수행하고, 얻어진 직교 행렬 Q_B를 A와 C에 적용한다. 두 번째 단계가 핵심으로, A를 블록‑패널 구조로 나누어 각 패널을 CPU가 Householder 반사기로 처리하고, 그 반사에 의해 발생하는 업데이트 연산을 CPU와 GPU가 동시에 수행한다. 여기서 업데이트 연산는 주로 대규모 행렬‑행렬 곱(GEMM) 형태이므로, GPU의 대용량 병렬 연산 능력을 활용해 데이터 이동을 최소화한다. 또한, 패널 처리와 업데이트를 오버랩함으로써 CPU와 GPU 사이의 대기 시간을 크게 줄인다.
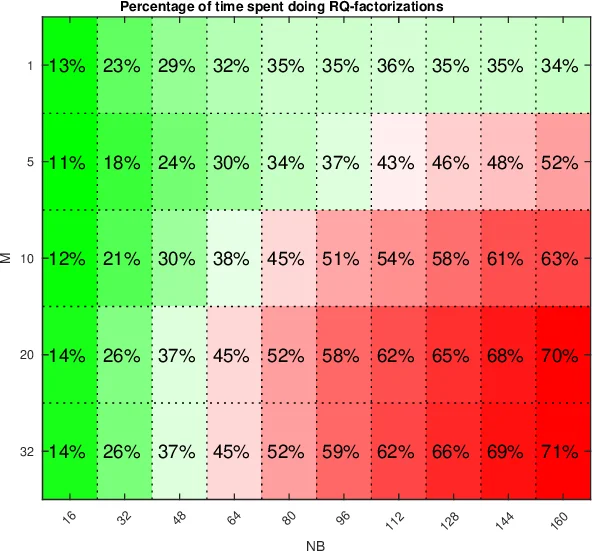
변환이 끝난 뒤에는 m‑헨시버그‑삼각 시스템을 GPU에서 직접 해결한다. 시프트 σ는 메모리 제한을 고려해 배치 단위로 묶이며, 각 배치 내 모든 시프트에 대해 동일한 m‑서브대각선(즉, m‑헨시버그 구조)의 소거를 동시에 수행한다. 이 과정은 각 시프트에 대한 RQ 분해를 필요로 하는데, 저자는 작은 행렬에 대한 RQ 분해를 스레드 블록 단위로 병렬화하고, 나머지 행렬 업데이트는 cuBLAS의 고성능 BLAS3 루틴에 맡긴다. 결과적으로, 시프트 수가 수천 개에 달해도 GPU 메모리와 연산 자원을 효율적으로 활용해 동시 다중 시프트 해결이 가능해진다.
알고리즘의 실용성을 입증하기 위해 저자들은 IRKA(Iterative Rational Krylov Algorithm)와 같은 모델 차원 축소 기법에 적용하였다. IRKA에서는 매 반복마다 2r 개의 시프트 시스템을 풀어야 하는데, 제안된 하이브리드 솔버를 사용하면 전체 실행 시간이 기존 CPU 전용 구현 대비 5~10배 가량 단축된다. 또한, 전형적인 전이 함수 평가, 구조적 ε‑pseud스펙트럼 계산 등에서도 동일한 가속 효과가 관찰되었다.
전체적인 설계는 CPU‑GPU 협업을 극대화하면서도 데이터 이동을 최소화하고, BLAS3 연산을 중심으로 구성함으로써 현대의 다중코어·다중GPU 환경에 최적화된 직접 해법을 제공한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기