초고속 적색편이 군집화: 바이어 초거리와 SDSS 데이터 적용
초록
바이어 거리(최장 공통 접두사 기반 초거리)를 이용해 O(n) 시간 복잡도로 계층적 군집을 구성한다. 이를 SDSS의 약 50만 개 천체에 적용해 스펙트럼 적색편이(z_spec)를 포토메트릭 적색편이(z_phot)와 매핑하는 지역적 회귀 모델을 제시한다.
상세 분석
본 논문은 전통적인 병합형 계층 군집(agglomerative hierarchical clustering)이 요구하는 O(n²) 연산량을 극복하기 위해 바이어 거리(Baire distance)를 도입한다. 바이어 거리는 두 실수값을 문자열 형태(소수점 이하 자리수)로 변환한 뒤, 가장 긴 공통 접두사의 길이를 기반으로 정의되는 초거리이며, 자연스럽게 초계량(ultrametric) 구조를 만든다. 이 초계량은 트리 형태의 p‑adic(또는 m‑adic) 코딩과 동등하게 해석될 수 있어, 각 데이터 포인트를 자리수별 “빈”(bin)으로 바로 매핑함으로써 한 번의 스캔만으로 계층적 클러스터를 구축한다. 따라서 전체 연산량은 n·ℓ (ℓ은 사용된 자리수 깊이)으로, 실질적인 O(n) 시간 복잡도를 달성한다.
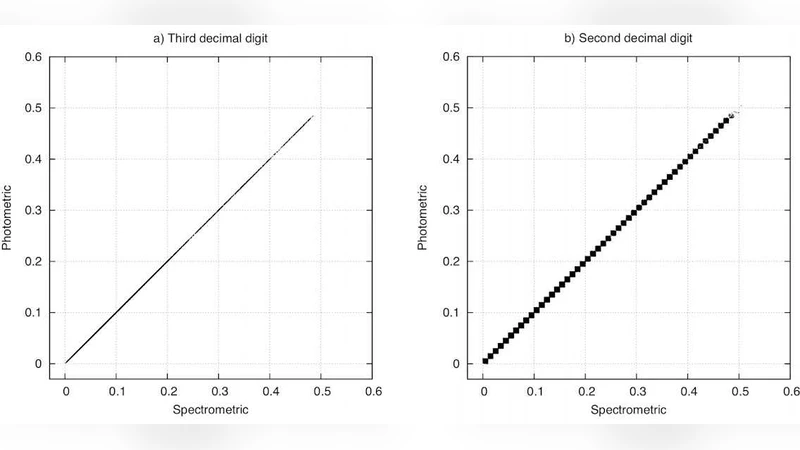
SDSS 데이터셋에 적용할 때는 z_spec와 z_phot를 01 구간으로 정규화하고, 소수점 이하 최대 34자리까지를 고려한다. 동일한 자리수 접두사를 공유하는 데이터는 같은 클러스터에 할당되며, 접두사의 길이가 길수록 두 적색편이 값 간의 상관관계가 강해진다. 논문은 0.0~0.6 구간의 적색편이 443 094개를 분석했으며, 1자리(61.14%), 2자리(19.40%), 3자리(2.07%) 등 다양한 접두사 길이에 따른 클러스터 비율을 제시한다. 특히 3자리까지 일치하는 경우가 전체의 약 21.7%를 차지해, 높은 정밀도의 매핑이 가능함을 보여준다.
클러스터별 평균 오차와 신뢰 구간을 이용해 지역적 최근접 이웃 회귀(clusterwise nearest neighbor regression)를 수행한다. 이는 전역적인 선형 회귀나 다층 퍼셉트론과 달리, 동일 접두사를 가진 소규모 집단 내에서 최적의 변환 함수를 학습하도록 설계되었다. 실험 결과, 바이어 기반 클러스터링은 k‑means와 유사한 군집 구조를 재현하면서도 연산 속도가 수십 배 이상 빠른 것으로 확인되었다.
또한, 초계량 구조가 데이터 압축과도 연결된다는 점을 강조한다. 동일 접두사를 공유하는 문자열은 서로를 부분적으로 압축할 수 있어, 메모리 사용량을 최소화하면서도 트리 탐색이 효율적으로 이루어진다. 이러한 특성은 대규모 천문 데이터베이스에서 실시간 질의와 빠른 매핑이 요구되는 상황에 특히 유리하다.
결론적으로, 바이어 초거리를 활용한 O(n) 계층 군집화는 천문학적 대규모 데이터셋에서 스펙트럼 적색편이를 포토메트릭 적색편이로 예측하는 새로운 로컬 회귀 프레임워크를 제공한다. 초계량 기반 트리 코딩은 계산 복잡도와 메모리 효율성을 동시에 개선하며, 향후 다른 연속형 과학 데이터에도 일반화 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기