인간 불확실성이 예측 데이터 마이닝 평가에 미치는 숨은 영향
초록
본 논문은 인간의 판단 변동성(불확실성)이 추천 시스템 등 예측 모델의 평가 지표(RMSE 등)에 편향을 일으키고, 알고리즘 순위 결정에 오류 확률을 발생시킴을 수학적으로 증명한다. 확률적 모델링과 가우시안 오류 전파, 몬테카를로 시뮬레이션을 활용해 불확실성 전파를 정량화하고, 순위 오류를 최소화하는 방안을 제시한다.
상세 분석
논문은 먼저 인간 의사결정이 시간·기분·미디어 리터시 등 다양한 요인에 의해 변동한다는 실증적 사실을 제시하고, 이를 “인간 불확실성”이라 정의한다. 기존 평가 지표(RMSE, MAE, MAP 등)는 단일 점수로 취급돼 이러한 변동성을 무시한다는 근본적인 한계를 지적한다. 저자는 각 사용자‑아이템 쌍의 평점을 확률 변수, 즉 개별 정규분포(μ,σ²)로 모델링한다. 이렇게 하면 평점 자체가 확률적이며, 평점과 예측값의 차이 제곱을 합산한 RMSE도 복합 확률 변수 Z=g(X₁,…,X_N) 로 표현된다.
복합 확률 변수의 분포는 기본 변수들의 컨볼루션으로 정의되지만, 직접 계산은 비현실적이다. 따라서 두 가지 접근법을 제안한다. 첫째, 대규모 데이터에서는 중심극한정리를 이용해 Z가 근사적으로 정규분포를 따른다고 가정하고, 1차 테일러 전개를 통해 기대값과 분산을 구한다(가우시안 오류 전파). 둘째, 작은 샘플이나 검증을 위해 몬테카를로 시뮬레이션을 수행해 실제 분포를 추정한다. 실험에서는 Netflix 데이터(2.8M 평점)에서 Monte‑Carlo가 35시간이 소요될 정도로 계산 비용이 높음을 보여준다.
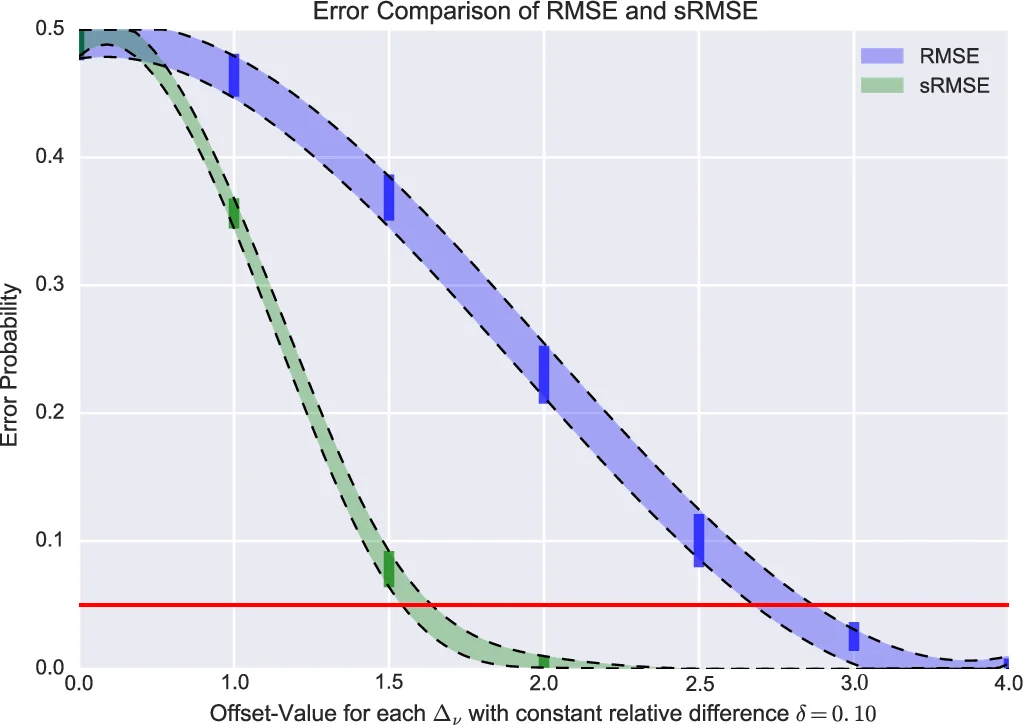
이후 두 알고리즘의 RMSE를 각각 Z₁∼N(μ₁,σ₁²), Z₂∼N(μ₂,σ₂²) 로 가정하고, 순위 오류 확률 P(Z₁≥Z₂)=Φ((μ₁−μ₂)/√(σ₁²+σ₂²)) 를 도출한다. 즉, 평균 차이가 작고 분산이 클수록 순위가 뒤바뀔 확률이 커진다. 실험에서는 동일 사용자·아이템에 대해 세 가지 추천기(R₁,R₂,R₃)를 적용했을 때, RMSE 히스토그램이 겹쳐 순위가 35% 정도는 뒤바뀔 수 있음을 확인한다.
마지막으로 논문은 불확실성을 고려한 평가 프레임워크를 제시한다. (1) 각 평점에 대한 σ를 추정해 가중 평균 RMSE를 계산하고, (2) 순위 오류 확률을 사전 계산해 통계적 유의성을 검증한다. 또한, 불확실성을 감소시키는 방법으로 다중 평가, 베이지안 사후 평균, 혹은 신뢰구간 기반 순위 결정을 제안한다. 이러한 접근은 단순 점수 비교가 아닌, 확률적 순위 판단을 가능하게 하여 연구·산업 현장에서 과도한 투자나 잘못된 모델 선택을 방지한다.
댓글 및 학술 토론
Loading comments...
의견 남기기