비디오 프레임과 보상을 동시에 예측하는 딥러닝 모델
초록
본 논문은 Atari 게임 환경에서 고차원 영상 입력을 이용해 시스템 동역학과 보상 함수를 하나의 심층 신경망으로 공동 학습한다. 기존의 비디오 프레임 예측 네트워크에 보상 예측용 소프트맥스 층을 추가하고, 영상 재구성 손실과 보상 교차 엔트로피 손실을 결합한 복합 목표함수를 최적화한다. 5개의 게임에 대해 200프레임까지 누적 보상을 정확히 예측함으로써 모델 기반 강화학습의 가능성을 제시한다.
상세 분석
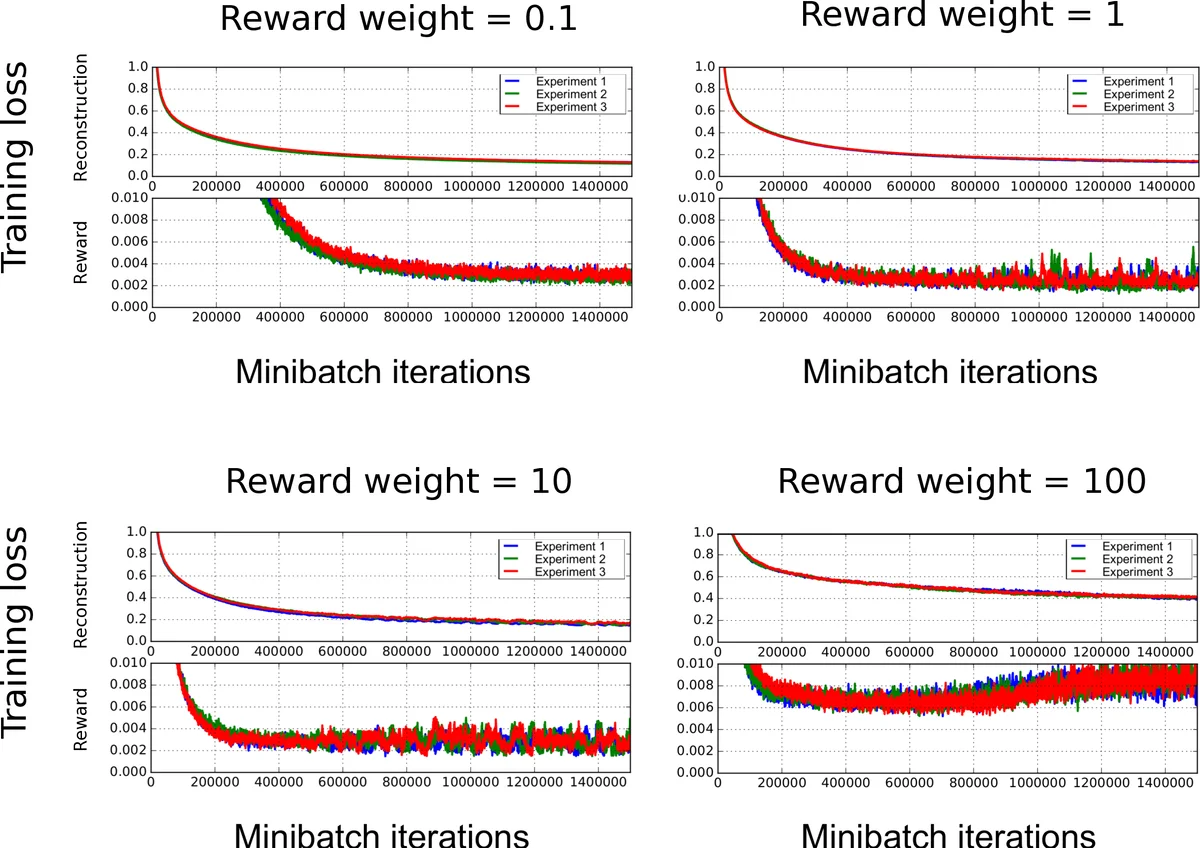
이 연구는 모델 기반 강화학습에서 가장 큰 난관 중 하나인 “고차원 시각 입력으로부터 환경 동역학과 보상 구조를 동시에 학습”하는 문제를 해결하고자 한다. 기존의 모델 프리 DQN은 대량의 샘플을 필요로 하지만, 본 논문은 Oh et al. (2015)의 비디오 프레임 예측 네트워크를 기반으로 하여 두 가지 주요 확장을 수행한다. 첫째, 행동을 원-핫 인코딩한 뒤 압축된 잠재 표현과 원소별 곱셈을 통해 행동‑조건부 변환을 수행하는 기존 구조를 유지하면서, 동일한 잠재 공간에서 현재 보상을 예측하도록 소프트맥스 출력층을 추가하였다. 둘째, 학습 목표를 영상 재구성 L2 손실과 보상 예측을 위한 교차 엔트로피 손실을 λ 로 가중합한 복합 손실 L_K(θ) 로 정의하였다. 이때 λ는 두 손실 간 트레이드오프를 조절하며, K와 T는 각각 예측 시계열 길이와 재현 횟수를 의미한다.
학습 과정에서는 커리큘럼 학습을 적용해 초기에는 짧은 예측 단계(K=1)부터 시작해 점진적으로 예측 horizon을 늘려가며 장기 예측 능력을 강화한다. 이는 비디오 프레임 예측에서 흔히 발생하는 오류 누적 문제를 완화시키는 전략이다. 또한, 보상은 Atari 환경에서 클리핑된 -1, 0, +1의 세 가지 값만을 갖도록 전처리하고, 이를 원-핫 벡터로 변환해 소프트맥스 출력과 비교한다.
실험은 Q*bert, Seaquest, Freeway, Ms. Pac‑Man, Space Invaders 다섯 게임에 대해 수행되었다. 테스트 셋은 약 5만 프레임, 1천 개의 트라젝터리를 사용해 100‑step까지 누적 보상을 예측했으며, 누적 보상 오차의 경험적 분포를 baseline(마진 보상 분포 샘플링)과 비교하였다. 결과는 20‑step 이상에서도 평균 오차가 크게 감소하고, 200‑step까지도 의미 있는 예측 정확도를 유지함을 보여준다. 특히 영상 재구성 손실만을 최적화한 경우 보상에 민감한 특징을 놓칠 수 있었지만, 복합 손실을 사용함으로써 보상‑관련 시각 정보를 잠재 공간에 효과적으로 인코딩했다는 점이 강조된다.
이 논문의 주요 기여는 (1) 비디오 프레임과 보상을 공동으로 예측하는 단일 네트워크 설계, (2) 복합 손실을 통한 잠재 표현의 보상 민감도 강화, (3) 장기 누적 보상 예측에 성공함으로써 모델 기반 RL, 특히 Dyna‑style 플래닝이나 MCTS와 같은 방법에 바로 적용 가능한 환경 모델을 제공한다는 점이다. 한계로는 현재는 프레임 재구성을 거쳐 보상을 예측하지만, 실제 플래닝 단계에서는 잠재 공간에서 직접 다음 상태를 예측하는 “shortcut” 모델이 필요함을 언급한다. 또한, 보상 클리핑에 의존하므로 연속적이고 복잡한 보상 구조를 가진 환경에 대한 확장 가능성은 추가 연구가 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기