의료 기록 속 위해 사건, AI가 찾아낸다
초록
의료 오류로 인한 환자 위해는 주요 사망 원인 중 하나입니다. 본 연구는 임상 현장에서 작성된 자연어 형태의 사고 보고서를 분석해, 환자에게 실제 위해가 발생했는지와 그 심각도 수준을 자동으로 분류하는 딥러닝 모델을 제안합니다. 주의 메커니즘을 결합한 CNN과 RNN 기반 모델이 기존 방법을 크게 능가하는 성능을 보였습니다.
상세 분석
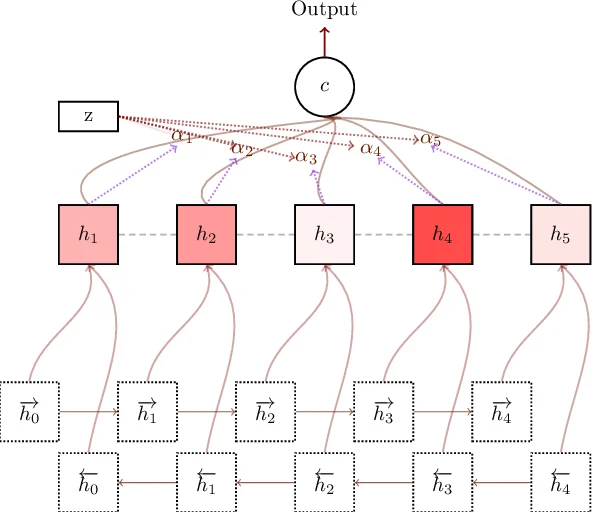
본 연구의 기술적 핵심은 복잡한 의료 서술문의 계층적 특징을 포착하기 위해 설계된 하이브리드 신경망 아키텍처에 있습니다. 모델은 1) 임베딩 레이어, 2) 합성곱 신경망(CNN) 레이어, 3) 순환 신경망(RNN) 레이어, 4) 주의 메커니즘(Attention Mechanism)으로 구성됩니다.
먼저, CNN 레이어는 지역적 문맥(예: 특정 약물명과 부작용을 함께 언급한 구문)에서 중요한 특징(n-gram 수준)을 추출하는 역할을 합니다. 이어지는 RNN 레이어는 CNN이 추출한 이러한 지역 특징들의 시퀀스 전체에 걸친 장기적 의존성과 흐름(예: 초기에는 위해 없음으로 보고되었으나, 후속 검사에서 골절이 발견된 경우의 논리적 연결)을 모델링합니다. 여기서 LSTM이나 GRU가 사용되었을 가능성이 높으나, 논문 본문에서는 명시적으로 구체화하지 않았습니다.
가장 중요한 혁신은 여기에 도입된 주의 메커니즘입니다. 긴 보고서 텍스트에서 최종 분류 결정에 가장 크게 기여하는 특정 단어나 구문(예: “fracture”, “administered wrong dose”, “resulted in”)에 모델의 ‘주의’를 집중시킵니다. 이는 RNN이 장기 의존성을 학습하는 데 있어서 발생할 수 있는 정보 소실 문제를 완화하고, 해석 가능성을 일부 제공한다는 점에서 의미가 있습니다.
기존 연구가 Bag-of-Words, SVM 등 전통적인 머신러닝에 의존하거나 단일 CNN/RNN을 적용한 반면, 본 연구의 하이브리드 접근법은 지역 패턴 인식(CNN), 시퀀스 모델링(RNN), 중요도 가중치 부여(Attention)라는 세 가지 핵심 기능을 통합했습니다. 이를 통해 단순한 키워드 매칭을 넘어서, 사건의 전후 맥락과 원인-결과 관계를 포함한 보고서의 복잡한 내러티브 구조를 이해하는 데 더욱 근접했습니다. 결과적으로 특징 공학 없이 원본 텍스트만으로도 높은 성능을 달성하여, 다양한 의료 기관의 서식 차이에 대한 일반화 가능성을 보였습니다.
댓글 및 학술 토론
Loading comments...
의견 남기기