연속 인증을 위한 무라벨 스마트폰 움직임 패턴 활용
초록
본 논문은 라벨이 없는 스마트폰 가속도계 데이터를 이용해 사용자의 움직임 패턴을 자동으로 클러스터링하고, 각 컨텍스트별 인증 모델을 구축해 연속 인증을 구현한다. 57명의 참가자를 5~12일간 수집한 데이터로 5가지 머신러닝 알고리즘을 평가했으며, 랜덤 포레스트가 평균 5.6%의 EER로 가장 우수한 성능을 보였다.
상세 분석
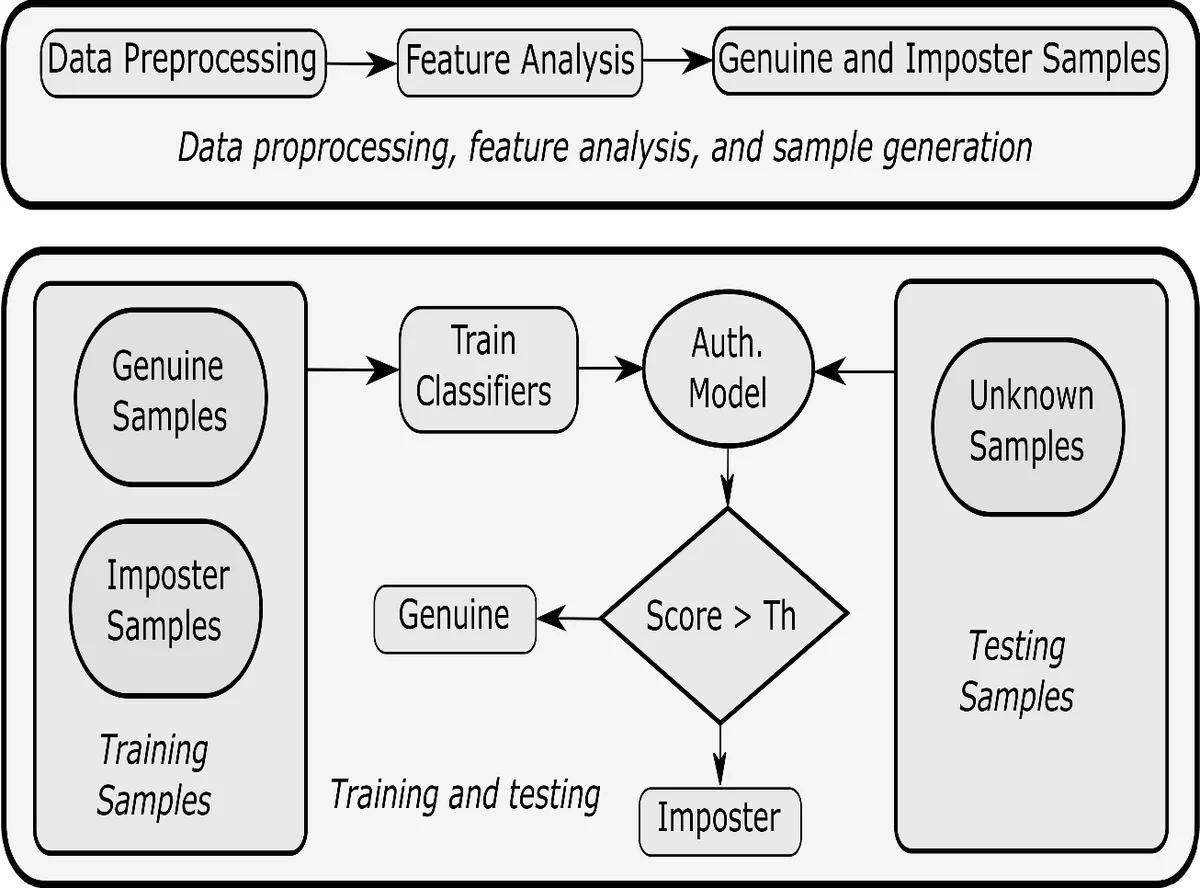
이 연구는 기존 연속 인증 연구가 대부분 라벨링된 데이터와 제한된 실험 환경에 의존한다는 한계를 극복하고자, 완전한 무라벨, 비제한 환경에서 수집된 가속도계 데이터를 활용한다는 점에서 혁신적이다. 데이터 수집 단계에서 참가자들의 일상적인 스마트폰 사용을 방해하지 않도록 백그라운드 서비스만 실행했으며, 샘플링 레이트가 기기마다 다름을 감안해 시간 기반 윈도우(10초, 5초 오버랩)로 전처리하였다. 이는 실제 모바일 환경에서 발생할 수 있는 불균형과 노이즈를 자연스럽게 반영한다.
컨텍스트 식별을 위해 K‑means 클러스터링을 적용하고, 각 사용자의 클러스터 인덱스를 라벨로 사용해 Context Identification Model(CIM)을 학습한다. 흥미로운 점은 클러스터를 실제 인간 활동(걷기, 타이핑 등)과 매핑하려 하지 않고, 순수히 데이터의 구조적·통계적 유사성에 기반해 구분한다는 점이다. 이를 통해 사용자마다 서로 다른 컨텍스트 수와 분포가 존재함을 확인했으며, 최대 8개의 클러스터를 설정했지만 데이터가 부족한 클러스터는 제외하였다.
특징 추출 단계에서는 시간·주파수·정보 이론 기반 특성을 20여 개 이상 사용했으며, DTW 거리, 스펙트럴 엔트로피, 상호 정보, 화면 온/오프 비율 등을 포함한다. 이후 각 컨텍스트·사용자별로 상관 기반 특징 선택을 적용해 평균 70% 이상의 특성을 제거, 차원 축소와 정규화를 수행했다. 이렇게 정제된 특징 집합을 바탕으로 로지스틱 회귀, 인공 신경망, k‑NN, SVM, 랜덤 포레스트 5가지 분류기를 학습시켰다.
평가 결과, 랜덤 포레스트가 평균 5.6%의 Equal Error Rate(EER)를 기록하며 가장 낮은 오류율을 보였고, SVM(10.7%), k‑NN(12.1%), 신경망(13.5%), 로지스틱 회귀(13.7%) 순으로 성능이 나타났다. 통계적 유의성 검증을 위해 Friedman 테스트와 Nemenyi 사후 검정을 수행했으며, 랜덤 포레스트와 다른 모델 간 차이가 유의미함을 확인했다. 또한 Failure‑to‑Enroll 정책을 적용해 사용자의 데이터 양·품질에 따른 시스템 적합성을 분석했으며, 데이터가 충분히 확보된 사용자에서는 높은 인증 정확도를, 데이터가 부족한 경우에는 등록 실패율이 상승함을 보고했다.
이 논문의 주요 공헌은 (1) 라벨이 없는 일상 데이터셋 구축, (2) 자동 컨텍스트 클러스터링 기반 다중 인증 모델 설계, (3) 다양한 머신러닝 알고리즘의 비교 및 통계적 검증, (4) 실제 사용 환경에서의 적용 가능성을 Failure‑to‑Enroll 분석을 통해 조명한 점이다. 한계로는 가속도계 외의 센서(자이로, 마이크 등)를 활용하지 않았으며, 클러스터 수를 고정한 점, 그리고 라벨이 없는 상태에서 컨텍스트 해석이 어려워 실제 서비스 적용 시 사용자 피드백이 필요할 수 있다는 점을 들 수 있다. 향후 연구에서는 멀티모달 센서 융합, 동적 클러스터 수 최적화, 그리고 실시간 경량 모델 구현을 통해 배터리 소모와 지연 시간을 최소화하는 방향으로 확장될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기