TV 시트콤 대본을 활용한 감정 인식: 순차적 CNN 모델의 새로운 시도
초록
본 논문은 미국 시트콤 ‘Friends’ 대본을 기반으로 7가지 감정을 라벨링한 대규모 대화 코퍼스를 구축하고, 발화 순서를 고려한 4가지 순차적 CNN(SCNN) 모델에 주의 메커니즘을 결합하여 감정 분류 성능을 향상시켰다. 최종 모델은 미세 감정(7가지)에서 37.9%, 대분류 감정(긍정·부정·중립)에서 54%의 정확도를 기록한다.
상세 분석
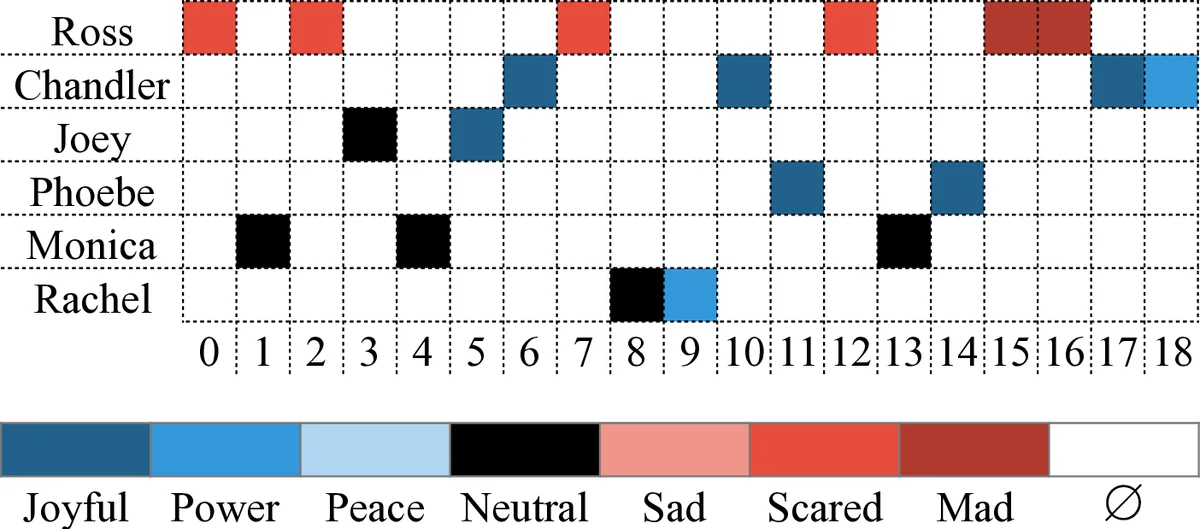
이 연구는 텍스트 기반 감정 인식 분야에서 대화형 데이터의 부족을 메우기 위해 ‘Friends’의 전체 대본을 수집·전처리하고, 12,606개의 발화에 대해 7가지 감정(슬픔, 분노, 공포, 힘, 평화, 기쁨, 중립)을 크라우드소싱으로 라벨링하였다. 라벨링 과정에서 Cohen·kappa가 14% 수준으로 낮게 나타났지만, 부분 동의율이 85%에 달해 다수 의견을 반영한 투표·랭킹 방식을 통해 75.5%의 발화에 확정 라벨을 부여했다. 감정 분포는 중립과 기쁨이 전체의 절반 이상을 차지해 불균형이 존재했으며, 이는 코미디 장르 특성으로 해석된다.
모델 설계에서는 기존 CNN이 순차 정보를 활용하지 못한다는 한계를 극복하고자 두 가지 시퀀스 통합 방식을 제안한다. 첫 번째 방식(SCNN‑c)은 현재 발화와 이전 k‑1 발화의 특징 벡터를 열 방향으로 연결한 뒤 1‑D 컨볼루션을 적용해 시간적 의존성을 학습한다. 두 번째 방식(SCNN‑v)은 현재 발화와 이전 발화의 특징을 각각 2‑D 컨볼루션으로 추출한 뒤, 두 결과를 다시 1‑D 컨볼루션에 입력해 보다 풍부한 상호작용을 모델링한다. 양 모델 모두 어휘 수준의 n‑gram 특징을 잡아내는 Conv1과, 발화 간 감정 흐름을 포착하는 Conv2를 병렬로 사용한다.
주목 메커니즘은 정적 임베딩(단어 수준)과 동적 임베딩(컨볼루션 후 특징) 사이에 가중치를 학습함으로써, 현재 발화가 이전 발화의 감정 상태에 얼마나 의존하는지를 자동으로 조절한다. 실험 결과, 주의가 없는 기본 CNN 대비 SCNN‑c와 SCNN‑v가 각각 35%p, 46%p 정확도 향상을 보였으며, 주의가 결합된 SCNN‑v‑att가 최고 성능을 기록했다.
또한, 미세 감정(7가지)과 대분류 감정(긍정·부정·중립) 두 가지 라벨링 스킴을 동시에 평가했는데, 대분류에서는 감정 간 경계가 명확해 54%라는 비교적 높은 정확도를 달성했다. 이는 대화 텍스트만으로도 감정 흐름을 어느 정도 파악할 수 있음을 시사한다. 한계점으로는 라벨링의 주관성, 감정 불균형, 그리고 발화 길이와 슬랭·은유 등 비표준 언어 요소가 모델 성능에 미치는 영향이 남아 있다. 향후 멀티모달(음성·영상) 데이터와 더 정교한 라벨링 체계 도입이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기