참조 없이 NLG 품질을 예측하는 신경망 기반 평가 모델
초록
본 논문은 의미표현(MR)과 생성된 문장을 각각 GRU 인코더에 입력해, 두 마지막 은닉 상태를 결합해 품질 점수를 직접 예측하는 참조 없는 품질 추정(QE) 모델을 제안한다. 인공 오류를 삽입한 합성 데이터를 활용한 데이터 증강으로 Pearson 상관계수를 최대 21% 향상시켰으며, 전통적인 BLEU·METEOR·ROUGE·CIDEr와 비교해 일관되게 높은 상관성을 보였다.
상세 분석
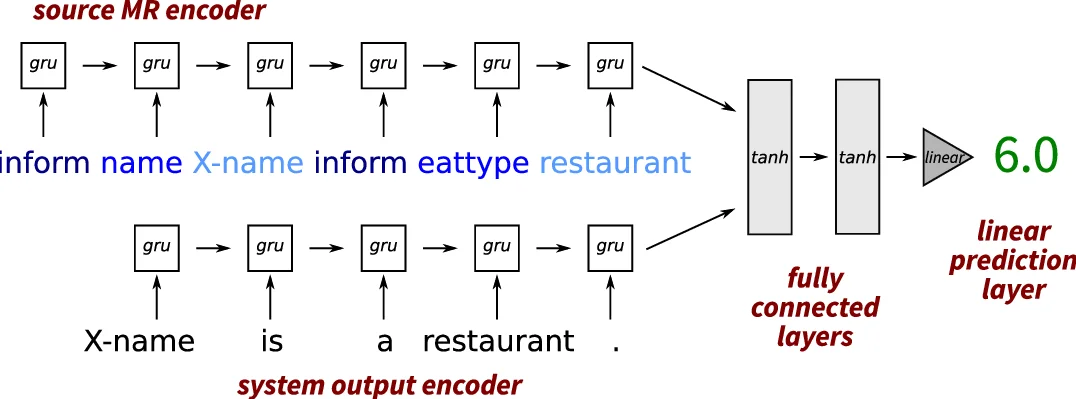
이 연구는 자연어 생성(NLG) 시스템의 출력 품질을 인간이 만든 레퍼런스 없이도 자동으로 추정할 수 있는 방법을 제시한다. 핵심 아이디어는 의미표현(MR)과 시스템 출력 두 텍스트를 별도의 GRU 기반 인코더에 순차적으로 입력하고, 각각의 최종 은닉 상태(h_M, h_S)를 연결(concatenation)한 뒤 완전 연결층(tanh)과 선형 회귀층을 거쳐 연속적인 품질 점수(1~6 Likert)를 출력하는 것이다. 모델은 토큰 임베딩을 무작위 초기화 후 학습 중에 함께 최적화하며, 입력에 dropout을 적용해 과적합을 방지한다.
데이터는 세 가지 NLG 시스템(LOLS, RNNLG, TGen)의 출력과 해당 MR을 크라우드소싱으로 수집한 인간 평가 점수를 이용해 5‑fold 교차 검증으로 학습·평가하였다. 인간 평점의 평균 상관계수는 0.45 정도로 다소 낮은 편이었지만, 모델은 이 평균을 기반으로 학습해 평균 절대오차(MAE)와 RMSE 측면에서 상수 베이스라인(평균 4.5)보다 우수했다.
특히, 합성 데이터 증강이 핵심적인 역할을 한다. 원본 학습 샘플에 대해 단어 삭제·복제·삽입·대체 등 5가지 오류 유형을 무작위로 적용해 새로운 학습 인스턴스를 만들고, 오류 수만큼 인간 평점을 1점씩 낮추는 방식이다. 이렇게 생성된 데이터는 원본 샘플 수를 3배 이상 늘려주어, Pearson 상관계수를 0.27 수준에서 0.33~0.35 수준으로 끌어올렸다(통계적으로 유의미). 추가로, 인간이 만든 레퍼런스 문장을 최대 점수(6)로 가정하고 동일한 오류 삽입 과정을 적용했을 때도 약간의 성능 향상이 관찰되었다.
실험 결과는 BLEU·METEOR·ROUGE·CIDEr와 같은 전통적인 단어‑오버랩 기반 메트릭이 모두 0.070.09 수준의 Pearson 상관을 보인 반면, 제안 모델은 0.270.35 수준을 기록해 확연히 우수함을 입증한다. 또한, Spearman 순위 상관도 일관되게 개선돼, 모델이 인간 평가의 순위 구조를 잘 포착함을 보여준다. 다만, RMSE가 약간 높게 나타난 점은 모델이 평균적인 예측은 잘하지만 일부 극단적인 오류에 대해서는 큰 편차를 보일 수 있음을 시사한다.
전반적으로 이 논문은 NLG 품질 추정에 있어 레퍼런스 의존성을 완전히 제거하면서도 실용적인 성능을 달성했으며, 합성 데이터 활용이 작은 데이터셋에서 성능을 크게 끌어올릴 수 있음을 실증한다. 향후 대화 시스템의 실시간 품질 모니터링, 출력 재랭킹, 혹은 저품질 출력에 대한 규칙 기반 백업 전략 등에 직접 적용 가능할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기