클라우드 서비스 평가를 위한 부스팅 메트릭: 벤치마크 스위트 활용의 마지막 단계
초록
본 논문은 클라우드 서비스 평가 시 다수의 벤치마크 결과를 하나의 종합 지표로 통합하는 “부스팅 메트릭” 개념을 제안한다. 공간적 평균(산술·기하·조화·제곱 평균)과 레이더 플롯 기반 면적 계산이라는 두 가지 초기 방법을 소개하고, Amazon EC2 인스턴스 사례를 통해 이러한 메트릭이 실험 설계와 의사결정에 어떻게 활용될 수 있는지를 보여준다.
상세 분석
논문은 클라우드 서비스 평가에서 벤치마크 스위트를 사용하더라도 개별 결과만 제시되는 경우가 많아 전체적인 성능을 직관적으로 파악하기 어렵다는 문제점을 지적한다. 이를 해결하기 위해 머신러닝의 “부스팅” 개념을 차용, 여러 약한(weak) 측정값을 하나의 강한(strong) 지표로 결합하는 ‘부스팅 메트릭’이라는 새로운 프레임워크를 제시한다.
첫 번째 접근은 n‑차원 유클리드 공간에서 각 벤치마크 결과를 좌표값으로 보고, 해당 점과 원점이 형성하는 직육면체의 기하학적 특성을 이용한다. 여기서 산술 평균은 직육면체의 둘레, 기하 평균은 부피, 조화 평균은 부피와 표면적의 비율, 제곱 평균은 원점과 점 사이의 거리(유클리드 노름)와 대응한다. 이러한 평균값들은 계산이 간단하고, 동일한 단위·스케일을 가진 동질적인 메트릭에 적용 가능하다는 장점이 있다. 그러나 서로 다른 단위·측정 기준을 사용하는 벤치마크(예: FLOPS vs. latency)에는 직접 적용하기 어렵다.
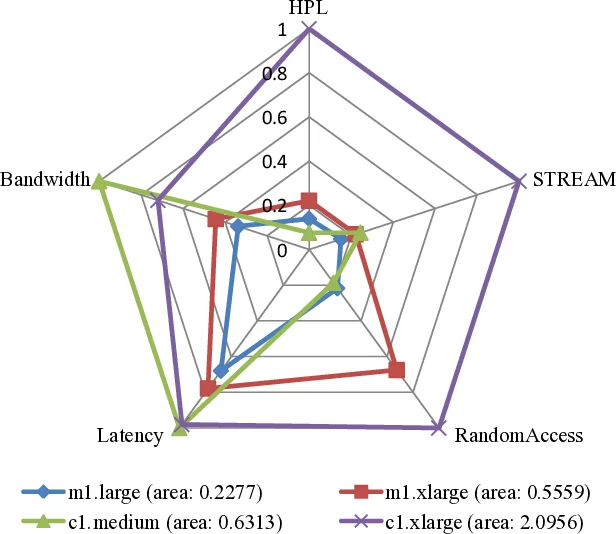
두 번째 접근은 레이더 플롯을 활용한다. 서로 다른 단위의 결과를 ‘Higher‑Better’와 ‘Lower‑Better’로 구분한 뒤, 각각을 0‑1 구간으로 정규화한다. 정규화된 값들을 방사형으로 배치해 다각형을 만들고, 그 면적을 계산해 하나의 수치형 부스팅 메트릭으로 변환한다. 면적은 모든 축에서 고르게 높은 값을 가질수록 커지므로, 종합 성능을 직관적으로 비교할 수 있다. 또한 면적 자체가 실험 설계에서 응답 변수(Response)로 활용될 수 있어 통계적 분석에 바로 연결된다.
논문은 HPCC 벤치마크 결과를 이용해 네 종류의 EC2 인스턴스를 평가하고, 정규화·레이더 플롯·면적 계산 과정을 상세히 제시한다. 결과는 c1.xlarge가 전반적으로 가장 우수함을 보여주며, 면적 값(2.0956)과 다른 인스턴스의 면적을 직접 비교함으로써 의사결정에 필요한 요약 정보를 제공한다.
추가 사례에서는 NPB‑Java 벤치마크를 사용해 m1.xlarge와 m2.xlarge 두 인스턴스의 실행 시간과 FLOP‑rate에 기하 평균을 적용, 동일한 단위·측정값을 갖는 경우 평균 기반 부스팅 메트릭이 효과적임을 확인한다. 전체적으로 논문은 부스팅 메트릭이 “요약 응답 변수” 역할을 수행함으로써 실험 설계(요인 분석, ANOVA 등)와 결과 해석을 간소화한다는 점을 강조한다. 한계점으로는 정규화 방법에 따른 가중치 편향, 다중 목표(성능 vs. 비용) 통합 시 가중치 설정의 주관성, 그리고 복합적인 비선형 관계를 포착하기 어려운 점을 언급한다. 향후 연구에서는 가중치 최적화, 다목적 최적화 기법, 머신러닝 기반 비선형 결합 모델 등을 탐색할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기