유전 프로그래밍 기반 특성 엔지니어링: 적합도와 생존 전략의 심층 비교
초록
본 논문은 기존 회귀용 FEW(FEature Engineering Wrapper)를 분류 문제에 적용하고, 특성 생성에 사용되는 적합도 함수와 개체 생존 메커니즘을 체계적으로 평가한다. 실험 결과, 실루엣 점수를 변형한 적합도가 Fisher 기준보다 우수했으며, ε‑lexicase 생존 방식이 가장 높은 성능을 보였다. FEW는 여러 전통적 분류기와 비교했을 때 일부 데이터셋에서 최고 성능을 향상시켰으며, 생물의학 데이터에서도 의미 있는 특성을 일관되게 도출하였다.
상세 분석
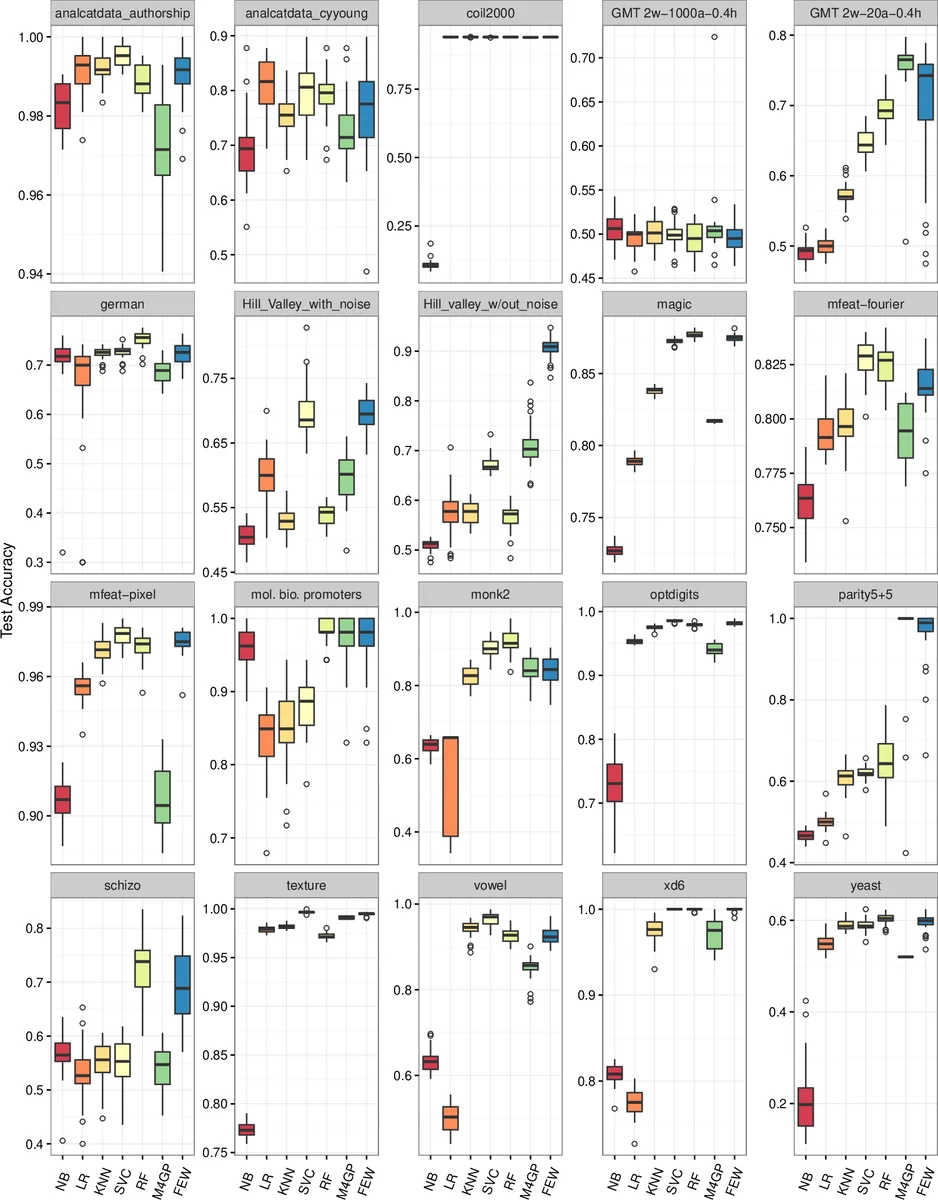
FEW는 GP(Genetic Programming) 개체들을 개별 특성 변환 ϕ(x) 로 간주하고, 전체 개체 집합 Φ(x)를 하나의 피처 매트릭스로 구성한 뒤, 외부 머신러닝(ML) 모델에 입력한다. 이때 GP는 변환 자체를 진화시키며, 적합도 평가는 변환이 클래스 구분에 얼마나 기여하는가에 초점을 맞춘다. 논문은 세 가지 적합도 함수를 비교한다. 첫 번째는 전통적인 R²(결정계수)이며, 연속형 레이블에만 적합하고 다중 클래스에서는 레이블 순서 가정을 강제한다. 두 번째는 Fisher 기준으로, 클래스 평균 간 거리와 분산을 이용해 평균적인 구분력을 측정한다. 세 번째는 실루엣 점수를 기반으로 한 적합도로, 각 샘플의 내부 군집 응집도(aᵢ)와 가장 가까운 이웃 군집과의 분리도(bᵢ)를 비교해 sᵢ = (bᵢ−aᵢ)/max(aᵢ,bᵢ) 를 구하고 전체 평균을 사용한다. 실험 결과, 실루엣 기반 적합도가 특히 다중 클래스 문제에서 가장 높은 분류 정확도를 유도했으며, Fisher 기준은 경우에 따라 과도한 레이블 순서 의존성을 보여 성능이 떨어졌다.
생존 메커니즘 측면에서는 네 가지 방식을 평가한다. 토너먼트 생존은 무작위 2개 개체를 비교해 적합도가 높은 개체를 유지한다. 결정적 군집(Deterministic Crowding)은 자식과 가장 유사한 부모와만 경쟁하도록 하여 다양성을 보존한다. ε‑lexicase 생존은 각 훈련 샘플을 무작위 순서로 선택하고, 해당 샘플에서 ε 이하의 적합도 차이를 보이는 개체들을 남겨다음 라운드로 진행한다. 마지막으로 무작위 생존은 전혀 선택 압력을 가하지 않는다. 실험에서는 ε‑lexicase가 가장 높은 평균 정확도를 기록했으며, 무작위 생존이 토너먼트와 결정적 군집보다 우수했다. 이는 ε‑lexicase가 개별 특성들이 서로 보완하도록 유도해, LR이나 SVC와 같이 상관관계에 민감한 ML 모델과의 시너지 효과를 극대화함을 의미한다.
또한, FEW를 다양한 전통적 분류기(LR, SVC, KNN, DT, RF, NB)와 최신 GP 기반 M4GP와 비교하였다. 모든 방법에 대해 5‑fold 교차 검증 기반 그리드 서치를 수행해 최적 하이퍼파라미터를 찾았으며, 20개의 공개 데이터셋에 대해 30번의 무작위 50/50 훈련‑테스트 분할을 수행했다. 결과적으로 FEW는 특히 비선형 관계가 강한 데이터에서 기존 최고 성능 분류기보다 평균 2~3%p의 정확도 향상을 보였고, 일부 데이터셋에서는 기존 최고 모델을 능가했다. 마지막으로, 생물의학 데이터(예: 질병 진단)에서 FEW는 서로 다른 ML 페어링(LR, SVC, RF 등)에도 일관된 의미 있는 특성(예: 특정 바이오마커 조합)을 자동으로 도출했으며, 도출된 특성은 도메인 전문가가 해석 가능한 형태였다.
요약하면, FEW는 적합도 설계와 생존 전략을 통해 GP 기반 특성 생성의 효율성을 크게 향상시킬 수 있음을 입증했으며, 특히 실루엣 기반 적합도와 ε‑lexicase 생존이 조합될 때 최고의 성능을 발휘한다. 이는 GP를 단순히 모델 자체로 사용하기보다, 강력한 ML 모델과의 하이브리드 형태로 활용할 때 실용적 가치를 높일 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기