도메인 인식 대화 시스템
초록
본 논문은 대화 중 도메인 전환을 고려한 도메인 인식 챗봇 모델인 DOM‑Seq2Seq를 제안한다. SVM 기반 도메인 분류기와 RNN 기반 분류기, 도메인별 Seq2Seq 응답 생성기, 그리고 재순위화 모듈을 결합해 현재 발화와 이전 발화들의 도메인 정보를 활용한다. 실험 결과, 기존 일반 Seq2Seq 대비 도메인 분류 정확도와 의미적 일치도에서 우수함을 보였다.
상세 분석
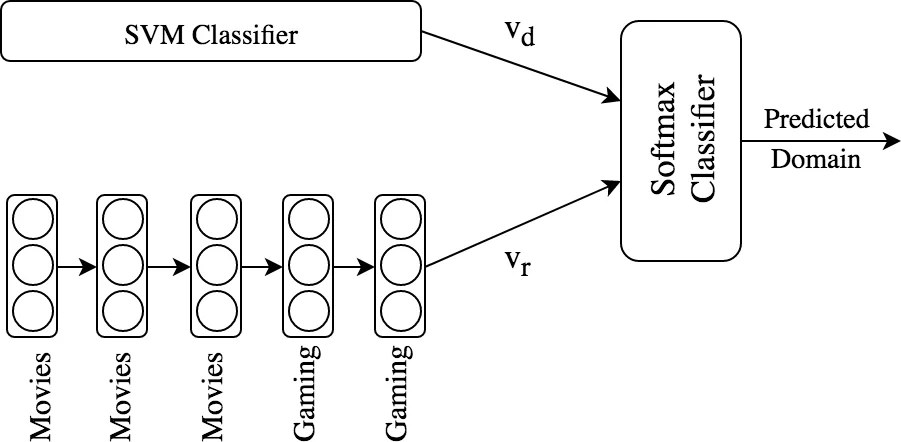
DOM‑Seq2Seq는 대화 흐름에서 도메인 전환을 명시적으로 모델링한다는 점에서 기존 Seq2Seq 기반 챗봇과 차별화된다. 전체 파이프라인은 네 단계로 구성된다. 첫 번째 단계는 도메인 분류기로, 저자는 두 가지 접근법을 제시한다. 하나는 tf‑idf 기반 SVM을 사용해 발화 수준의 단어 특징을 추출하고, 과거 세 발화의 실제 도메인(dₜ₋₁, dₜ₋₂, dₜ₋₃)과 SVM 예측값(d_SVMₜ)을 로지스틱 회귀에 입력해 현재 도메인을 예측하는 앙상블 방식이다. 두 번째는 도메인 시퀀스를 원‑핫 벡터로 인코딩한 뒤, 단일 레이어 RNN(8개의 은닉 유닛)으로 장기 의존성을 학습하고, 최종 은닉 상태와 SVM 출력 벡터를 concat하여 softmax로 도메인 확률을 산출한다. 이 두 방법은 각각 짧은 대화와 긴 대화에서 장점이 다르다.
두 번째 단계는 도메인별 응답 생성기로, 각 도메인(영화, 게임, OOD)에 대해 별도의 LSTM‑Seq2Seq 모델(3층, 1024 hidden)을 학습한다. 어텐션 메커니즘을 적용해 입력 문장의 중요한 토큰에 가중치를 부여한다. 디코더의 마지막 타임스텝 로그잇을 시그모이드로 정규화해 확률 p(rᵢ)로 변환한다.
세 번째 단계인 재순위화 모듈은 도메인 분류 확률 p(dᵢ)와 해당 도메인 응답 확률 p(rᵢ)를 곱해 가장 큰 값을 갖는 후보를 선택한다. 즉, argmax_i {p(dᵢ)·p(rᵢ)} 로 최종 응답을 결정한다. 이 설계는 도메인 예측이 불확실할 때도 응답 생성기의 신뢰도를 반영하도록 한다.
데이터는 Reddit의 AMA 스레드와 Twitter에서 수집했으며, LDA를 이용해 각 발화에 토픽(도메인) 라벨을 자동 부여했다. 영화와 게임 도메인 각각 1.3M·0.5M 쌍, OOD는 0.3M 쌍을 학습에 사용했으며, SVM 분류기는 0.54M 포스트로 학습·검증했다. 실험에서는 두 가지 자동 평가 지표를 사용했다. 첫째는 도메인 분류 정확도, 둘째는 GloVe 기반 Word Embedding Greedy Match 점수로, 이는 생성 응답과 실제 응답 간 의미적 유사성을 측정한다. 결과는 En‑DOM‑Seq2Seq가 77.57%의 도메인 정확도와 0.801의 Greedy 점수로, 기본 Seq2Seq(0.760)와 RNN‑DOM‑Seq2Seq(0.797)보다 모두 우수함을 보여준다. 정성적 예시에서도 DOM‑Seq2Seq는 보다 상황에 맞는, 정보량이 풍부한 답변을 제공한다.
한계점으로는 도메인 수가 제한적(3개)이며, 도메인 라벨링이 자동 LDA 기반이라 라벨 노이즈가 존재할 가능성이 있다. 또한 재순위화가 단순 곱셈에 의존해 확률 스케일 차이에 민감할 수 있다. 향후 연구에서는 다중 도메인 확장, 라벨링 품질 개선, 그리고 더 정교한 후보 선택(예: 학습 기반 메타‑리랭커) 등을 고려할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기